Какой алгоритм выбрать для ваших данных

Введение
Кластерный анализ — это соответствующая область науки о данных, которая позволяет группировать похожие объекты в отдельные подгруппы. Хотя существуют разные семейства алгоритмов кластеризации, наиболее широко известным является K-Means. Это алгоритм на основе центроида, означающий, что объекты в данных группируются путем присвоения ближайшему центроиду. Однако основная ошибка K-Means заключается в том, что он не обнаруживает выбросы или зашумленные точки данных, что приводит к их неправильной классификации. Кроме того, K-Means отдает предпочтение шаровым скоплениям и не очень хорошо работает с данными, состоящими из скоплений произвольной формы. Примером этого служит рис. 1, на котором показан набор данных [1], состоящий из шести отдельных кластеров произвольной конфигурации, окруженных зашумленными точками данных. K-Means (запущенный с n_clusters = 6) с трудом справляется с этими различными формами и, кроме того, присваивает все зашумленные точки данных кластерам.

Этот тип проблемы может быть решен с помощью алгоритма кластеризации на основе плотности, который характеризует кластеры как области с высокой плотностью, отделенные от других кластеров областями с низкой плотностью. Двумя популярными алгоритмами в этой области являются DBSCAN (пространственная кластеризация на основе плотности для приложений с шумом) и его иерархический преемник, HDBSCAN.
ДБСКАН
Этот алгоритм [2] группирует данные на основе плотности и обычно требует равномерной плотности внутри кластера и падения плотности между кластерами. Он имеет два основных параметра, которые необходимо тщательно выбирать для получения оптимальных результатов:
- eps: радиус, определяющий окрестности вокруг каждой точки данных.
- min_samples: минимальное количество точек данных, необходимое в районе, чтобы точка данных считалась базовой точкой.
DBSCAN классифицирует точки данных по трем категориям:
- Основная точка: точка, имеющая не менее min_samples точек данных в радиусе eps.
- Пограничная точка: точка, которая имеет менее min_samples, но по крайней мере одну основную точку по соседству.
- Шум: точка, которая не является ни центральной, ни пограничной точкой и имеет менее min_samples точек в своем окружении.
Алгоритм начинает со случайного выбора точки и, если требования к параметрам соблюдены, начинает назначать точки данных кластерам. Затем кластеры расширяются путем рекурсивного вычисления окрестности вокруг каждой точки данных до тех пор, пока не будут посещены все точки. Отличный наглядный гайд с описанием алгоритма DBSCAN можно найти в этом посте.
HDBSCAN
HDBSCAN — недавно разработанный алгоритм [3], основанный на DBSCAN, который, в отличие от своего предшественника, способен идентифицировать кластеры различной плотности. Алгоритм начинается очень похоже, находя базовое расстояние каждой точки данных. Однако, в отличие от DBSCAN, который использует eps в качестве границы соответствующей дендрограммы, HDBSCAN сжимает дендрограмму, просматривая разбиения, которые дают лишь небольшое количество точек, отделяющихся как точки, выпадающие из кластера. В результате получается меньшее дерево с меньшим количеством кластеров, теряющих баллы (рис. 2), которое затем можно использовать для выбора наиболее стабильных и устойчивых кластеров.

Размер сохраняемых кластеров определяется единственным обязательным входным параметром HDBSCAN:
- min_cluster_size: минимальное количество точек данных для формирования кластера.
Этот параметр определяет, выпадают ли точки из кластера или разделяются на два новых кластера. Что позволяет этот процесс, так это то, что результирующее дерево можно спиливать на разной высоте и собирать кластеры с разной плотностью в зависимости от их стабильности.
Более подробное объяснение базовой функциональности HDBSCAN можно найти в его соответствующей документации.
Сравнение
Параметры
DBSCAN может быть чрезвычайно эффективным, если пользователь обладает некоторыми знаниями предметной области об имеющихся данных. В частности, это относится к параметру eps, который менее интуитивно понятен и обычно требует некоторого знания (или тонкой настройки) близости, в пределах которой точки данных должны быть назначены кластеру (см. этот пост для более подробной информации). HDBSCAN, напротив, с единственным обязательным параметром min_cluster_size кажется более интуитивным.
Шум
DBSCAN очень чувствителен к шуму (рис. 3), что может привести к неправильной кластеризации. HDBSCAN, хотя и не идеален, обычно более осмотрителен при назначении зашумленных точек данных кластерам.

Переменная плотность
DBSCAN имеет тенденцию не идентифицировать кластеры с неравномерной плотностью. Эта проблема послужила основной причиной разработки HDBSCAN, в результате чего он гораздо лучше справляется с кластерами различной плотности (рис. 4).
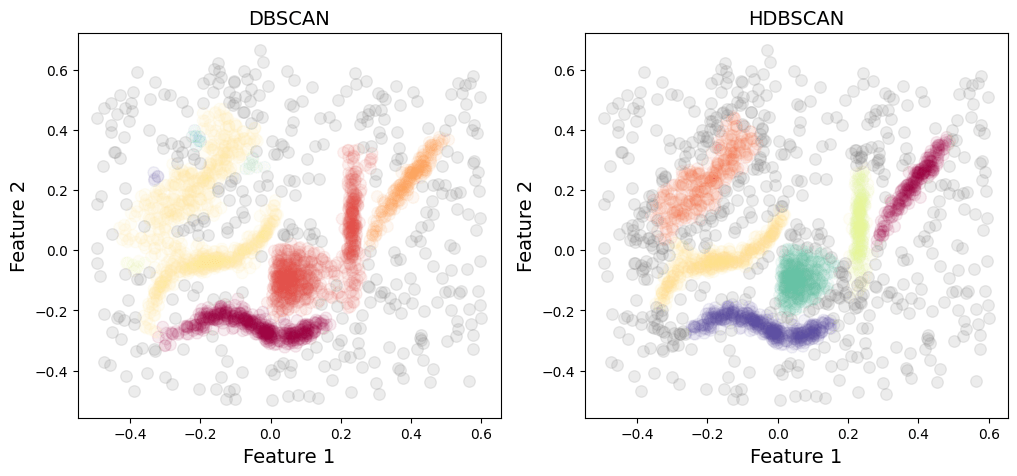
Производительность
Исследования масштабируемости также показывают, что HDBSCAN превосходит DBSCAN по вычислительной производительности по мере увеличения размера данных. На рисунке ниже показано, что при 200 000 точек данных HDBSCAN примерно в два раза быстрее, чем DBSCAN (рис. 5).
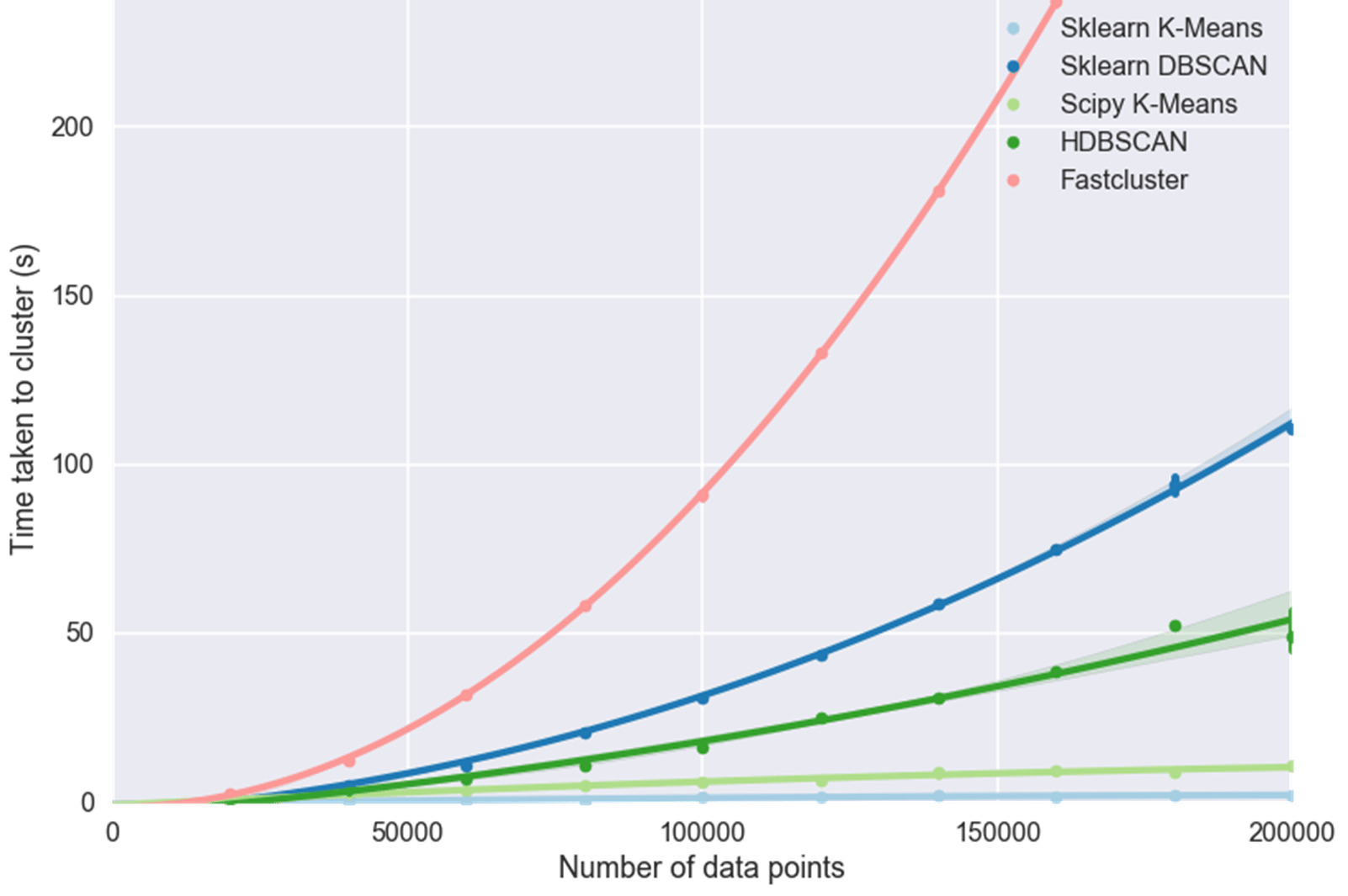
Заключение
Хотя и DBSCAN, и HDBSCAN хорошо работают с данными, содержащими шум и кластеры произвольной формы и размера, у них есть некоторые запутанные различия. Хотя дополнительный параметр DBSCAN eps может быть полезен, если у вас есть знания предметной области о ваших данных, его часто считают очень неинтуитивным параметром для настройки. Напротив, установка min_cluster_size для HDBSCAN кажется более интуитивно понятной. HDBSCAN также имеет преимущество, когда дело доходит до классификации шума и кластеров различной плотности. Наконец, HDBSCAN быстрее и эффективнее в вычислительном отношении, чем DBSCAN.
Рекомендации
[1] Л. Макиннес и др. (2017). «hdbscan: кластеризация на основе иерархической плотности». Journal of Open Source Software, The Open Journal, том 2, номер 11. 2017 г. [файл данных].
[2] Эстер и др. (1996). «Алгоритм на основе плотности для обнаружения кластеров в больших пространственных базах данных с шумом». KDD'96: Материалы Второй международной конференции по обнаружению знаний и интеллектуальному анализу данных, стр. 226–231.
[3] Кампелло и др. (2013). «Кластеризация на основе плотности на основе иерархических оценок плотности». PAKDD 2013: Достижения в области обнаружения знаний и интеллектуального анализа данных, стр. 160–172.






