
Линейная регрессия методом наименьших квадратов в Python
Как следует из названия, метод наименьших квадратов минимизирует сумму квадратов остатков между наблюдаемыми целями в наборе данных и цели, предсказанные линейным приближением. В этой статье мы увидим, как найти наиболее подходящую линию, используя линейную алгебру, а не что-то вроде градиентного спуска.
Алгоритм
Вопреки тому, что я думал изначально, реализация scikit-learn линейной регрессии минимизирует функцию стоимости вида:

используя сингулярное разложение X.
Если вы уже знакомы с линейной регрессией, вы можете увидеть некоторое сходство с предыдущим уравнением и среднеквадратичной ошибкой (MSE).
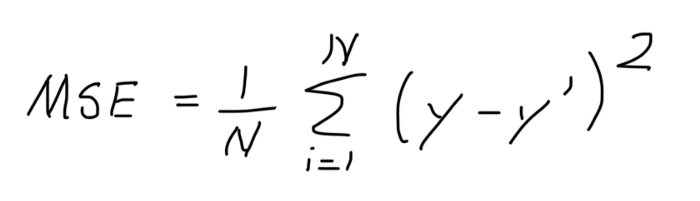
В качестве быстрого напоминания предположим, что у нас есть следующий график рассеяния и линия регрессии.
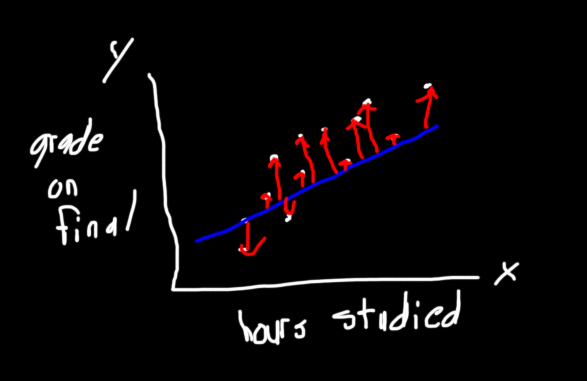
Мы вычисляем расстояние от линии до заданной точки данных, вычитая одно из другого. Мы возьмем квадрат разницы, потому что мы не хотим, чтобы прогнозируемые значения ниже фактических значений компенсировались значениями выше фактических. Математически последнее можно выразить следующим образом:
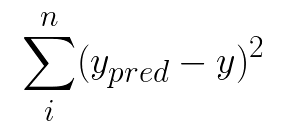

Функция стоимости, используемая в библиотеке scikit-learn, аналогична, только мы вычисляем ее одновременно с использованием матричных операций.
Те из вас, кто прошел курс математического анализа, наверняка уже сталкивались с подобными обозначениями раньше.
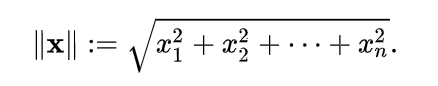
В данном случае x - вектор, и мы вычисляем его величину.
В том же смысле, когда мы окружаем переменную для матрицы (то есть A) вертикальными полосами, мы говорим, что хотим перейти от матрицы строк и столбцов к скаляру. Есть несколько способов получить скаляр из матрицы. В зависимости от того, какой из них используется, вы увидите другой символ справа от переменной (дополнительные 2 в уравнении не были добавлены случайно).
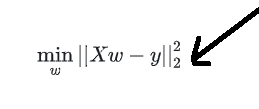
Дополнительные 2 означают, что мы берем евклидову норму матрицы.

Предположим, у нас есть матрица A, евклидова норма матрицы A равна квадратному корню из наибольшего собственного значения транспонированной точки A. Для ясности давайте рассмотрим пример.


Вот как мы количественно оцениваем ошибку. Однако здесь возникает новый вопрос. В частности, как мы на самом деле минимизируем его? Что ж, оказывается, решение (коэффициенты) методом наименьших квадратов с минимальной нормой может быть найдено путем вычисления псевдообратной матрицы входной матрицы X и умножения ее на выходной вектор y.

где псевдообратное к X определяется как:
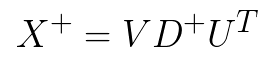
Все вышеперечисленные матрицы могут быть получены из разложения по сингулярным значениям (SVD) X. Напомним, что SVD X можно описать следующим образом:

Если вам интересно, как вы на самом деле определяете U, сигму и транспонирование V, посмотрите эту статью, которую я написал некоторое время назад, в которой рассказывается, как использовать SVD для уменьшения размерности.
Мы строим диагональную матрицу D ^ +, принимая значения, обратные значениям в матрице sigma. + относится к тому факту, что все элементы должны быть больше 0, поскольку мы не можем разделить на 0.
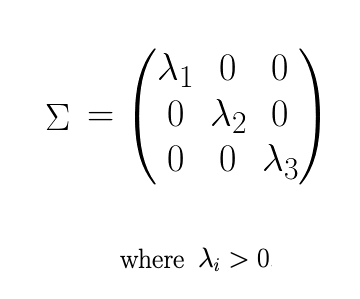

Код Python
Давайте посмотрим, как можно реализовать линейную регрессию с нуля, используя базовые numpy функции. Для начала импортируем следующие библиотеки.
from sklearn.datasets import make_regression from matplotlib import pyplot as plt import numpy as np from sklearn.linear_model import LinearRegression
Затем мы генерируем данные с помощью библиотеки scikit-learn.
X, y, coefficients = make_regression(
n_samples=50,
n_features=1,
n_informative=1,
n_targets=1,
noise=5,
coef=True,
random_state=1
)
Мы сохраняем ранг и количество столбцов матрицы как переменные.
n = X.shape[1] r = np.linalg.matrix_rank(X)
Мы находим эквивалент нашей матрице характеристик, используя разложение по сингулярным числам.
U, sigma, VT = np.linalg.svd(X, full_matrices=False)
Тогда D ^ + можно получить из сигмы.
D_plus = np.diag(np.hstack([1/sigma[:r], np.zeros(n-r)]))
V, конечно, равно транспонированию своего транспонирования, как описано в следующем тождестве.

V = VT.T
Наконец, мы определяем псевдообратную матрицу Мура-Пенроуза X.
X_plus = V.dot(D_plus).dot(U.T)
Как мы видели в предыдущем разделе, вектор коэффициентов можно вычислить, умножив псевдообратную матрицу X на y.
w = X_plus.dot(y)

Чтобы получить фактическую ошибку, мы вычисляем остаточную сумму квадратов, используя самое первое уравнение, которое мы видели.
error = np.linalg.norm(X.dot(w) - y, ord=2) ** 2

Чтобы убедиться, что мы получили правильный ответ, мы можем использовать функцию numpy, которая будет вычислять и возвращать решение методом наименьших квадратов для линейного матричного уравнения. Чтобы быть конкретным, функция возвращает 4 значения.
- Решение методом наименьших квадратов
- Суммы остатков (ошибка)
- Ранг матрицы (X)
- Сингулярные значения матрицы (X)
np.linalg.lstsq(X, y)
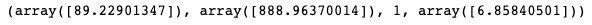
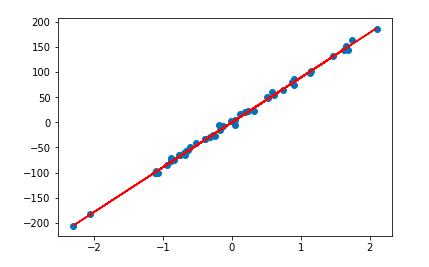
Мы можем визуально определить, действительно ли коэффициент приводит к оптимальному соответствию, построив линию регрессии.
plt.scatter(X, y) plt.plot(X, w*X, c='red')
Давайте сделаем то же самое, используя scikit-learn реализацию линейной регрессии.
lr = LinearRegression() lr.fit(X, y) w = lr.coef_[0]
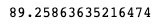
Наконец, мы строим линию регрессии, используя только что найденный коэффициент.
plt.scatter(X, y) plt.plot(X, w*X, c='red')






