Это сообщение в блоге резюмирует сеанс Dreamforce 2017, который был проведен во вторник, 7 ноября. Чтобы посмотреть этот сеанс, посмотрите эту запись!
Во второй день Dreamforce 2017 трио экспертов объяснили, как машинное обучение (ML) используется для поддержания ценности №1 в Salesforce: Trust. Посетители Dreamforce часто слышат о доверии и его значении в Salesforce. Для инфраструктуры доверие - это сочетание обеспечения безопасности, доступности и производительности для клиентов. Но по мере того, как количество данных, генерируемых инфраструктурой, растет в масштабе, способность обрабатывать и анализировать их с использованием традиционных процессов теряется. Однако алгоритмы машинного обучения могут успешно развиваться в среде больших данных.

Когда дело доходит до безопасности, анализ событий, фиксируемых в журналах, имеет решающее значение для выявления подозрительной активности. Но Salesforce генерирует десятки ТБ данных журнала в день. По словам ведущего Эрика Блоха, директора по продуктам безопасности Salesforce, для анализа всего 100 ГБ данных нужны два обученных сотрудника. Мало того, что ручной подход не масштабируется, нет достаточно квалифицированных потенциальных клиентов для найма, даже если бы он был масштабирован.
Механизмы правил могут до определенной степени обрабатывать большие данные. Но даже механизмы правил становятся нереально сложными, пытаясь обрабатывать объем данных, эквивалентный всему каталогу Библиотеки Конгресса США каждый день. И механизмы правил фиксируются в их понимании данных. Они не учатся. Например, Эрик указал на то, как потенциальные злоумышленники, пытающиеся взломать пароли, могут найти способ обойти механизм блокировки, основанный на 5 неудачных попытках входа в систему: они могут остановиться на 4 и внести изменения, чтобы избежать блокировки. Механизм правил не сможет определить шаблон, но алгоритм машинного обучения сможет связать источник неудачных попыток с другими параметрами, такими как поведение пользователя, и поднять флаг над аномальным шаблоном.
Одним из ключевых факторов, влияющих на доступность, является отказ компонента, и ни один аппаратный компонент не выходит из строя так часто, как жесткий диск. Salesforce генерирует миллиарды точек данных в день на многих тысячах машин, включая данные высокой мощности с жестких дисков. Так что просто передайте эти данные в алгоритм машинного обучения, верно? Не совсем так, - сказал Йони Майкл, инженер Salesforce, занимающийся улучшением методов прогнозирования сбоев жестких дисков в Salesforce. Поскольку в Salesforce используются жесткие диски различных поставщиков, и эти диски по-своему сообщают метрики и другую информацию, в результате получается очень неоднородный набор данных.
Одна правда о результатах ML заключается в том, что они хороши ровно настолько, насколько хорош исходные данные. Команда Йони сначала должна очистить и стандартизировать данные, передаваемые с жестких дисков, и только затем передать их алгоритмам машинного обучения, которые могут правильно соотносить сбои с конкретными условиями. Как только алгоритм будет должным образом обучен, он сможет начать предсказывать, какие жесткие диски могут выйти из строя и когда. Профилактический ремонт или замена этих дисков, которые являются ключевой частью инфраструктуры Salesforce, предотвращают проблемы, которые могут повлиять на доступность.
Производительность мобильных устройств и веб-сайтов настолько сложна, что не найти серебряной пули при попытках ее улучшить. В идеале оптимизация должна происходить как можно ближе к реальному времени, поскольку задержка в сети, пропускная способность и сбои могут влиять на миллионы сеансов одновременно. И где-то в каждом из этих сеансов клиент пытается выполнить задачу.
Мало того, что все больше данных перемещается на большие расстояния, но и современные сети и полезные нагрузки стали более нестабильными, чем когда-либо. Клиент может подключаться к сети Wi-Fi, сотовой или проводной сети, и данные могут быть зашифрованы. Она могла использовать мобильный телефон, ноутбук или другое устройство. Она может быть в том же городе или по всему миру. То, что она видит, может быть все на одном сервере или собрано из ресурсов, расположенных в двух или более удаленных местах. Добавьте к этому разные операторы связи, время суток и требования к качеству обслуживания, и это рецепт для создания огромного количества данных, которые нужно понять очень быстро.
Габриэль Тавридис, старший директор по инфраструктуре продуктов в Salesforce, объяснил, как EDGE от Salesforce, продукт на основе машинного обучения, предназначенный для оптимизации сетевых подключений, решает эту проблему. EDGE потребляет миллионы точек данных в минуту, а затем использует алгоритмы машинного обучения для их обработки и анализа. Наконец, EDGE дает действенные рекомендации по улучшению соединений. Но это еще не все.
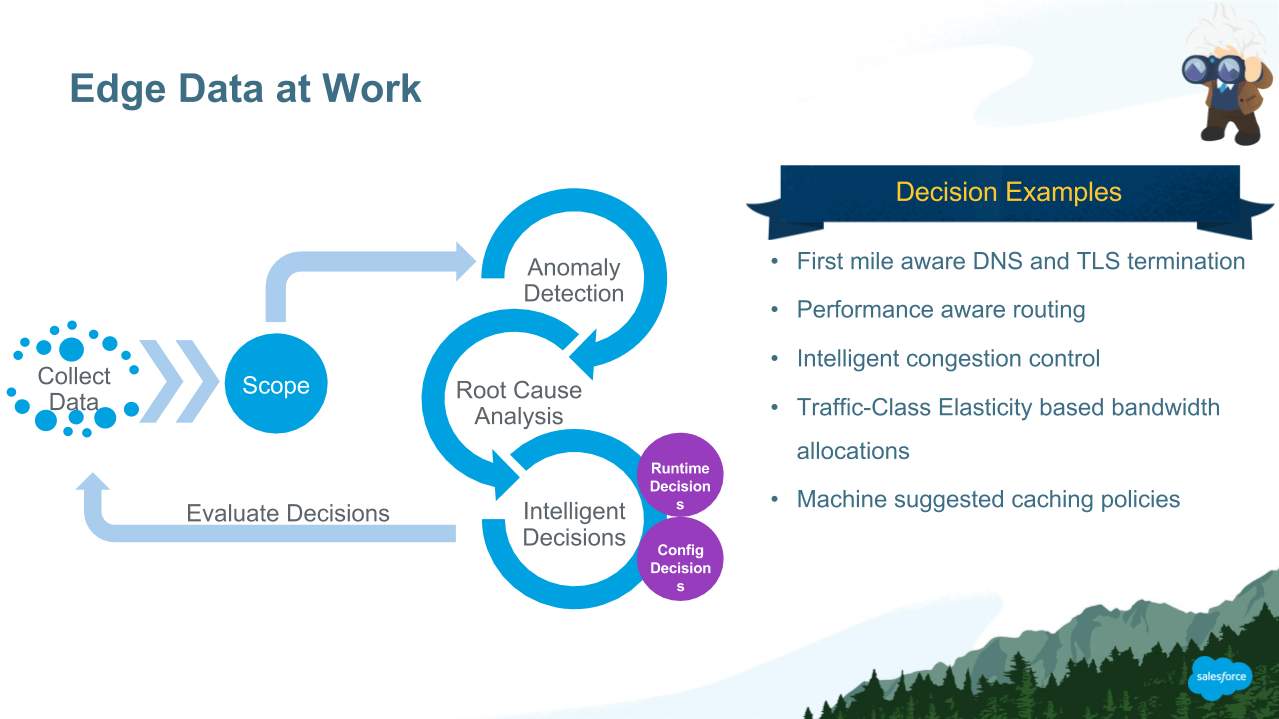
Как только решения будут приняты, EDGE снова сможет оценить их эффективность, чтобы лучше информировать будущие рекомендации. Маршрутизация соединения через определенный набор узлов, которая имела смысл вчера, например, завтра, возможно, придется переоценить для новых условий или другого контекста.
Четвертая промышленная революция принесла с собой несколько удивительных новых технологий, но также значительно увеличила объем данных для анализа. К счастью, он также предлагает новые передовые решения, способные не отставать от этих данных. Salesforce вводит новшества с этими решениями, чтобы повысить эффективность безопасности, предотвратить проблемы с оборудованием до того, как они возникнут, и сделать сети более интеллектуальными.
Следите за нами в Twitter: @SalesforceEng
Хотите с нами работать? Дайте нам знать!






