В этом посте я покажу трюк, как разделить большое число с помощью небольшого умножения на обратное. Я покажу два способа вычисления этих инверсий и как построить небольшую таблицу быстрого поиска. В процессе мы увидим, что одна инструкция иногда может быть дороже многих более дешевых инструкций!
В этом посте я создаю функцию для вычисления модульного мультипликативного обратного для модуля 2²⁵⁶. Учитывая число a, мне нужно число r, такое, что
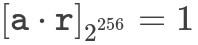
Запишем решение формально как

У этого числа r есть интересное свойство: умножение на r аналогично делению на a. Позвольте мне проиллюстрировать это на примере. Возьмите 1000 в качестве модуля и пусть a будет 73. Обратное 73 равно 137:

Если я хочу разделить 876 на 73, я могу умножить 876 на 137, что составляет 120 012, и взять последние три цифры, 12. На самом деле 876 = 12 · 73. Это интересный трюк для вечеринок.
Настоящая магия случается с большими числами. Допустим, мы хотим разделить 46 209 на 73. Для этого мы умножаем 209 на 137 и берем последние три цифры. Это 633 и действительно 46 209 = 663 · 73. Но подождите! Мы даже не использовали цифры 46! Как мы можем разделить число, даже не глядя на полное число? Этот трюк работает, когда 1) деление точное, 2) существует мультипликативная обратная величина и 3) результат умещается в трех цифрах.
Те, кто читал мой пост о 512-битном умножении, могут догадаться, к чему я клоню. Мы можем использовать это для деления на 512-битные числа с 256-битным умножением! Но прежде чем мы перейдем к этому, нам сначала нужен способ вычисления этих инверсий.
Теорема Ферма-Эйлера-Кармайкла
Эта забавная теорема - элементарный результат теории чисел. Все началось с маленькой теоремы Пьера де Ферма (1640 г.). Позже доказано и улучшено Леонардом Эйлером (1736 г.). Окончательно доведен до совершенства Робертом Кармайклом (1914). Теорема такова:
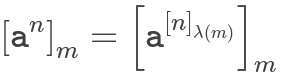
где λ(m) - функция Кармайкла. Это означает, что для чисел по модулю m показатели степени ведут себя как числа по модулю λ(m). Для нашего модуля λ(2²⁵⁶) = 2²⁵⁴. Таким образом, для 256-битных целых экспоненты ведут себя как 254-битные целые числа. Это также распространяется на отрицательные числа, и мы можем использовать это для получения модульных инверсий:

Solidity поддерживает возведение в степень, поэтому мы можем реализовать это напрямую:

Это компилируется в одну команду EXP с постоянной экспонентой, которая настолько коротка, насколько это возможно. Но на эту функцию уходит не меньше 1614 газа! Это связано с тем, что операция EXP требует 10 единиц газа плюс 50 единиц газа на каждый байт в экспоненте. В нашем случае показатель степени равен почти всем единицам, поэтому мы платим максимальную цену 1600.
Почему эта операция такая дорогая? В виртуальных машинах операция, скорее всего, реализована с использованием возведения в степень возведением в квадрат. В этом случае одна EXP инструкция выполняет тот же объем работы, что и 512 MUL инструкций. При пяти газах каждый эти MULs стоят около 2560 единиц газа. В свете этого, операция EXP стоит не так уж и странно. На самом деле, раньше он был немного дешевле, но это приводило к проблемам, и на EIP160 пришлось поднять цену.
Можем ли мы сделать лучше? да. Мы могли бы использовать расширенный алгоритм Евклида для решения r · a + 1 · m = gcd(a, m). Обычно это быстрее, чем возведение в степень. Но есть способ получше.
Обращение Ньютона-Рафсона-Гензеля
Метод Ньютона-Рафсона можно использовать для приблизительного деления вещественных чисел. Благодаря лемме Гензеля это работает даже лучше в модульной арифметике. Для степеней двойки это повторение:

Для нечетных чисел a значения этого повторения удовлетворяют формуле

Каждая итерация удваивает количество правильных битов. Это означает, что мы хотим вычислить r₈, чтобы получить модульное обратное значение для 256-битного числа.
Мы можем пропустить одну итерацию, наблюдая, что r₁ = a для всех нечетных значений a. Остается вычислить всего семь итераций.
Малая таблица поиска
Мы можем пропустить еще одну итерацию, создав небольшую таблицу поиска для r₂. Значения значений r₂, где существует инверсия, равны a ∈ {1, 3, 5, …, 15} с соответствующими инверсиями [1, 11, 13, 7, 9, 3, 5, 15].
Для других значений a мы используем ноль вместо реальных значений r₂. Использование нулей имеет то преимущество, что делает окончательный результат равным нулю, когда обратного не существует. Ноль никогда не может быть инверсным, так что это хорошее значение флага.

Инструкции, которые компилятор Solidity (v. 0.4.18) выдает из этого фрагмента, немного разочаровывают. Вставлена ненужная проверка границ. Для преобразования типа из uint8 в bytes1 выполняется умножение, которое немедленно отменяется делением для преобразования из bytes1 в uint256. Наконец, % 16 не заменяется более дешевым & 15. Давайте исправим все это:

Благодаря этим оптимизациям поиск в таблице дает чистую прибыль в несколько раз. Дальше идти пока не стоит. Для r₃ нам потребуется таблица поиска из 256 записей. Теоретически это можно сделать с помощью CODECOPY и MLOAD, но в настоящее время это не поддерживается. Для r₄ таблица должна быть 65 килобайт, что не соответствует размеру кода.
Заключение
Объединение таблицы поиска с шестью итерациями приводит к окончательной реализации:

Несмотря на то, что на эту функцию приходится в 20 раз больше операций, требуется всего около 154 газа. Менее 10% реализации на основе EXP!
Благодаря этой функции инверсии у меня наконец есть все инструменты, необходимые для решения проблемы, которую я хотел решить. В следующем посте я обойду ограничения и создам proportion функцию, которая никогда не дает сбоев.
Обновление: с тех пор я узнал, что r₂ = 3 * a ^ 2 работает вместо таблицы (Монтгомери, цитируется в Mayer 2016). Он немного дешевле и не требует сборки, но он не возвращает ноль, если обратного не существует.
Если вам нравятся эти сообщения и / или вы хотите побудить меня написать больше, хлопайте в ладоши и подписывайтесь!






