
Очистка данных означает исправление или удаление неверных данных или неважных данных в вашем наборе данных. Специалисты по данным тратят значительные усилия на очистку наборов данных и преобразование их в пригодные для использования форматы. Действительно, многие специалисты по данным утверждают, что на начальные этапы получения и очистки данных приходится 80% работы.
Плохие данные могут быть:
- Пустые ячейки
- Данные в неправильном формате
- Неверные данные
- Дубликаты
Во-первых, проверьте пропущенные даты
После импорта необходимых библиотек.
Сначала вам нужно будет предпринять шаги для проверки отсутствующих дат, мы будем использовать набор данных df_arabica_clean. Который переименовывается как coffee.csv.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
coffee = pd.read_csv('coffee.csv')
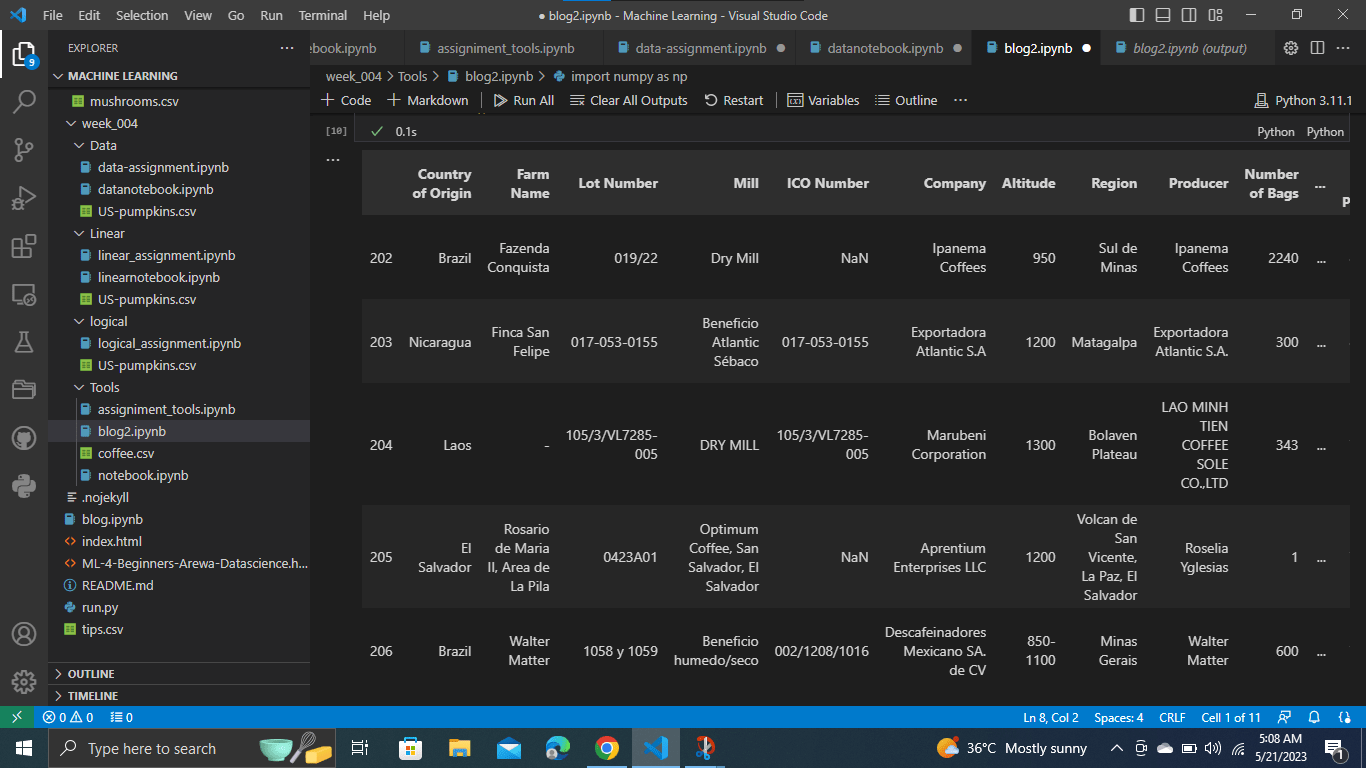
coffee.head()

Теперь мы можем видеть столбцы этого набора данных.

Последняя часть показывает, что у нас есть 5 строк и 41 столбец, это из функции head(). Когда мы смотрим на функцию tail(), мы видим последние 5 строк набора данных.
coffee.tail()
Чтобы получить всю информацию о данных, мы используем функцию info(). это даст вам общую информацию, которая вам нужна.
coffee.info()

Вы можете видеть, что наш набор данных имеет значение объекта и некоторые целые числа.
Мы также можем использовать функцию shape(), чтобы просто узнать количество строк и столбцов в наборе данных.
coffee.shape

Чтобы проверить пустую ячейку или отсутствующие данные.
coffee.isnull().sum()

Теперь мы можем удалить некоторые ненужные данные, которые нам не нужны из нашего набора данных.
to_drop = ['Unnamed: 0','Harvest Year',
'Grading Date','Owner',
'Processing Method','Status',
'Aftertaste','Uniformity',
'Clean Cup','Sweetness','Overall',
'Acidity']
coffee.drop(to_drop, inplace=True, axis=1)
Это удалит столбцы, указанные в квадратных скобках, поэтому теперь вы можете проверить функцию info(), чтобы увидеть, удалены ли столбцы.
Мы также можем сделать новый DataFrame из набора данных, который состоит только из данных, с которыми мы будем работать.
new_columns = ['Country of Origin', 'Company','Number of Bags', 'Moisture Percentage', 'Flavor', 'Color','Total Cup Points','Expiration'] coffee = coffee.drop([c for c in coffee.columns if c not in new_columns],axis=1) coffee.head()
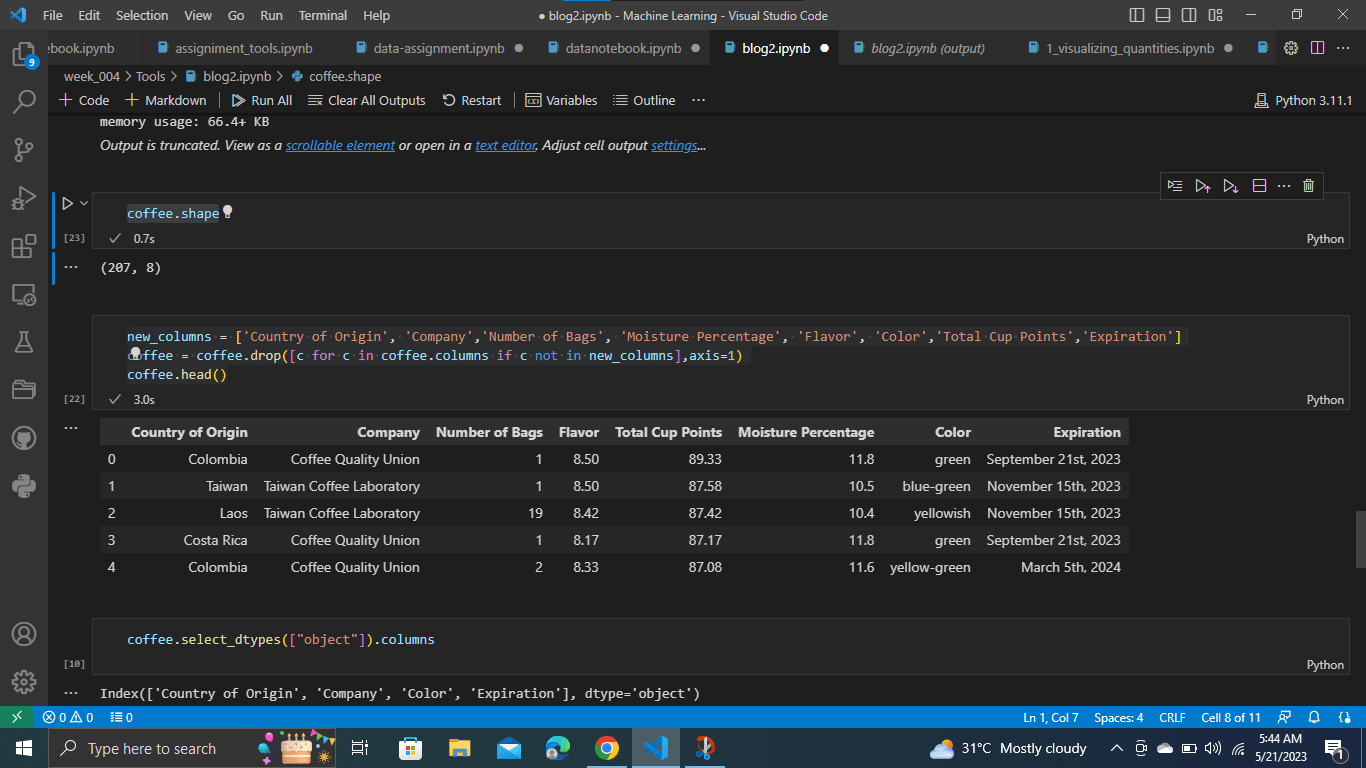
Вы можете видеть, что теперь ваш набор данных стал более читабельным и аккуратным.
В зависимости от вашей цели, многого можно добиться с помощью чистого и организованного набора данных. мы можем визуализировать эти данные с помощью различных диаграмм или придумать историю, которую вы хотите, чтобы ваши данные рассказали.
Пример.
x = coffee['Color'] y = coffee['Flavor'] plt.barh(x,y) plt.show()

Спасибо,
Удачной практики.






