Пакет для изучения языка го

Давайте рассмотрим замечательные встроенные пакеты, которые поставляются с Go, и то, что с ними можно делать. Я выберу некоторые из наиболее «непонятных», «сложных» и / или специальных пакетов Go, особенно те, которые отличают встроенную библиотеку языка от других языков.
Первая остановка - это пакет go / ast. Этот пакет используется для изучения представления синтаксического дерева пакета Go и может использоваться для выполнения статического анализа, линтинга кода, метапрограммирования и всего, что требует структурированной интерпретации исходного кода Go.
Это пошаговое руководство разбито на три части. Мы рассмотрим обход дерева AST, утверждения типа, извлечение литеральных значений из кода, извлечение комментариев и некоторое расширенное отражение структур. К его концу у нас будет утилита, способная извлекать документацию из микросервиса публикации NATS, в которой подробно описываются темы и типы сообщений, которые она создает. Вывод будет аналогичен спецификации Swagger, но для систем обмена сообщениями о событиях.
Часть 1 этой статьи посвящена основам пакета go / ast. Мы расскажем, что такое AST, обход дерева, функции посетителей, утверждения типов и то, как работают различные типы.
Начнем с простого. Что такое AST и что делает его ценным инструментом?
Абстрактные синтаксические деревья
Абстрактные синтаксические деревья, или сокращенно AST, представляют собой древовидные представления синтаксиса в исходном коде языка программирования. AST используются в качестве этапа компиляции и создаются на этапе анализа синтаксиса компилятора. AST похожи на деревья синтаксического анализа, однако они находятся на более высоком уровне, поскольку не включают все детали синтаксиса. Например, AST будут предоставлять больше структуры и контекста вокруг группировок в скобках, операторов if / else и циклических конструкций. В дополнение к этому, AST удалит ненужную информацию, такую как символы, операторы и другие токены, и вместо этого каждый узел будет представлять определенную операцию в языке. AST предоставляют семантическое представление программы или представление со смыслом и контекстной информацией, а не просто структурированное представление маркеров / текста, присутствующих в исходном коде.
Компиляторы обычно выполняют следующие первые шаги при компиляции исходного кода. Мы остановимся после фазы синтаксического / семантического анализа, так как это уровень, на котором сопоставляется пакет Ast Go Go.
- Лексирование: учитывая таблицу всех токенов (символов / слов), составляющих язык, лексический анализатор объединяет токены и маркирует их соответствующим образом.
- Анализ синтаксиса. Каждый язык имеет определенные правила синтаксиса, которым он должен следовать. На основе выходных данных лексического анализатора синтаксический анализатор построит дерево синтаксического анализа, которое представляет операции и синтаксис языка. Например, следующие токены «2, +, 2» будут сгруппированы в дерево синтаксического анализа следующим образом:
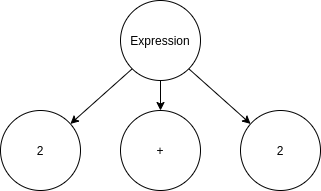
- Анализ синтаксиса / семантический анализ. Затем компилятор проверит дерево синтаксического анализа, чтобы убедиться, что оно имеет значение в контексте языка, и обычно добавляет семантику и контекст в дерево синтаксического анализа, а также удаляет ненужные конструкции. Здесь создается AST. AST приведенного выше выражения можно увидеть ниже:
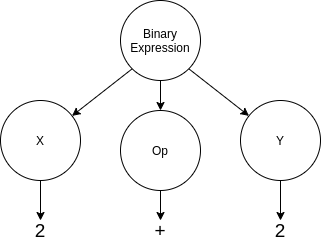
Обратите внимание, как AST идентифицирует структуру как двоичное выражение и соответственно маркирует левый операнд, оператор и правый операнд?
Пакет AST Go упрощает просмотр абстрактного синтаксического дерева языка. Эти низкоуровневые операции над языковыми конструкциями можно использовать для создания мощных инструментов повышения производительности труда разработчиков, а также для улучшения тестирования и обеспечения качества.
Извлечение структурированной документации
Вариант использования
Возможность автоматического извлечения документации из исходного кода - мощный инструмент, который может повысить продуктивность разработки и удовлетворить потребности конечных пользователей. Используя инструмент, который может автоматически создавать документацию из исходного кода, разработчики могут больше сосредоточиться на написании кода и меньше на написании документов, при этом предоставляя знания для использования конечным пользователем. Приведенное ниже сообщение в блоге посвящено этой концепции читабельности исходного кода, если вас интересует тема самодокументируемого кода.
За пределами исходного кода: читабельность и понимание
В серии публикаций« За пределами кода будет исследован исходный код, выходящий за рамки его использования в качестве набора инструкций, управляющих… medium.com »
Go имеет встроенный инструмент под названием godoc, который может автоматически извлекать комментарии из исходного кода Go и создавать веб-страницу, которая документирует функции и типы (пример здесь). Этот инструмент чрезвычайно мощный, несмотря на свою простоту, но что, если нам нужно что-то, что предоставляет больше контекста и описания функциональности? Давайте используем пакет go / ast для документирования микросервиса NATS.
NATS
NATS - это система обмена сообщениями о событиях на базе Go, легкая, отказоустойчивая и удобная в использовании. Одно из преимуществ NATS - простота его использования. Таким образом, NATS используется за кулисами с микрослужбами для выполнения передачи сообщений и взаимодействия запросов / ответов между службами. Иногда в приложениях может быть до сотен микросервисов, поэтому очень легко потерять информацию о том, какие микросервисы и что делают. Давайте создадим утилиту, которая может анализировать исходный код микросервиса, извлекать любые издатели сообщений NATS и предоставлять подробную информацию о темах и сообщениях, которые они создают. По сути, мы будем строить Swagger-подобную спецификацию для производителей мероприятий. Если вас интересует, как можно использовать NATS, ознакомьтесь с публикацией ниже:
Код
Мы будем использовать следующий пример кода в качестве микросервиса, который мы хотим задокументировать. Этот код будет публиковать сообщение по теме NATS каждые 5 секунд с надписью «Hello world!». Вероятно, наименее интересный микросервис из когда-либо созданных. Но эй, это может быть основанием для темы сердцебиения, чтобы гарантировать бесперебойную работу службы, верно? :)
Начиная с простого
Первым шагом является определение темы, по которой публикуется микросервис. Мы начнем с обхода всех вызовов функций в этом файле, поскольку метод «Опубликовать» является вызовом функции, а тема будет указана в первом аргументе вызова. С контекстуальной и семантической осведомленностью пакета AST Go сделать это довольно просто.
Давайте разберем этот код построчно. Начав с импорта, мы видим, что импортировано немного больше пакетов, чем было заявлено изначально, однако все они являются частью инструментария компилятора Go.
- go / ast предоставляет типы и методы для изучения абстрактного синтаксического дерева Go.
- go / parser предоставляет методы для анализа исходных файлов и создания абстрактных синтаксических деревьев.
- go / token предоставляет типы и методы для лексического процесса Go (токенизация)
Начнем с создания FileSet. FileSet предоставляет средства для токенизации и смещений (позиций) в группе исходных файлов. (Https://golang.org/pkg/go/token/#FileSet).
//Create a FileSet to work with fset := token.NewFileSet()
Затем мы используем функцию ParseFile пакета go / parser для синтаксического анализа исходного кода в AST. В этом случае AST доступен в переменной «файл», которая по сути является корневым узлом для AST, представляющего весь исходный файл.
file, err := parser.ParseFile(fset, "../nats_publisher/main.go", nil, parser.ParseComments)
В следующей части кода все становится интереснее. Пакет AST предоставляет функцию «проверки», которая принимает корневой узел и функцию посетителя. Функция посетителя принимает узел в качестве параметра и возвращает логическое значение. Функция inspect позволяет нам просматривать весь AST исходного файла, не беспокоясь о том, чтобы сначала искать в глубину или в ширину. Потому что давайте посмотрим правде в глаза, то, что мы больше всего ненавидим в рекурсии, - это то, что мы ненавидим больше всего в рекурсии.
В приведенной выше функции посетителя мы пытаемся привести узел к типу «CallExpr», который является выражением вызова. Выражение вызова - это когда из текущего узла вызывается другая функция. Если тип совпадает, мы печатаем вызов функции.
Улучшение
Теперь давайте улучшим нашу функцию посетителя, чтобы дополнительно изучить вызываемую функцию, а также параметры.
Сейчас здесь много всего! Но если разложить на части, все становится очень просто. Мы видим, что мы все еще проверяем, является ли узел выражением вызова, но затем мы начинаем идти немного дальше.
В строке 22 мы проверяем, является ли вызов функции выражением селектора - выражением, которое выбирает идентификатор из базового выражения в from ‹expression›. ‹Identifier›. Поскольку наши вызовы соединения с кодировкой NATS являются методами объекта, мы хотим убедиться, что проверяемая функция является выражением селектора.
Затем в строках 24–26 проверяется, является ли выбранное нами выражение идентификатором (чтобы не возникало ошибок приведения типов), а затем мы проверяем, работаем ли мы с функцией публикации. Это делается путем проверки имени нашего селектора, чтобы убедиться, что это метод публикации, и мы также проверяем, что идентификатор, который мы выбираем, является переменной «ec» или нашим закодированным соединением. Здесь сделаны некоторые предположения, например, метод публикации всегда вызывается напрямую (без упаковки), а переменная, содержащая наше закодированное соединение, называется «ec».
Как только мы сможем подтвердить, что функция является методом «ec.Publish», мы сможем распечатать тему. Используя немного больше обхода узла и утверждения типа, мы берем первый аргумент, преобразуем его в базовый литерал и получаем значение. Однако здесь мы могли бы повысить надежность, используя переключатель типа, подобный следующему:
Хотя в этом примере мы не рассматриваем далее случай, когда тема определяется идентификатором (переменной, константой, объектом и т. Д.), Можно исследовать дальше по дереву и получить фактическое значение, если оно получено из литерала. Если вы хотите по-настоящему фантазировать, вы даже можете использовать дополнительную функцию посетителя вместе с методом проверки для дальнейшего изучения узла и углубления в дерево, пока не дойдете до узла, имеющего буквальное значение темы.
Следующие шаги
Теперь, когда у нас есть извлеченная тема издателя, мы перейдем к предоставлению дополнительного контекста вокруг микросервиса. Мы можем добиться этого с помощью структурированных комментариев кода и способности парсера связывать группы комментариев с различными типами Go.






