Этот проект демонстрирует реализацию алгоритмов кластеризации — подмножества неконтролируемых моделей машинного обучения, целью которых является разделение совокупности объектов или, в данном случае, клиентской базы на несколько групп (кластеров), чтобы клиенты в одном кластере были более похожи ( на основе выбранных функций), чем клиенты, которые находятся в других кластерах.

Набор данных, изученный для этого проекта, состоит из 2240 записей из базы данных клиентов искусственного продуктового магазина. Цель проекта состоит в том, чтобы разделить этих покупателей на группы со схожими характеристиками, что позволит отделам маркетинга и продаж магазина лучше ориентировать продукты и рекламные акции на аудиторию, которая с большей вероятностью найдет отклик и ответит, тем самым способствуя улучшению индивидуального покупательского опыта. , удовлетворенность клиентов и, в конечном счете, доход магазина. Например, если мы знаем, что определенная группа покупателей реже посещает магазин, но тратит значительно больше, мы можем использовать эту информацию, чтобы повлиять на нашу следующую маркетинговую кампанию и сосредоточиться на дорогостоящих товарах.
Если читателю будут интересны необработанные данные, я предоставил ссылку на оригинальную веб-страницу Kaggle, где их можно скачать на досуге: https://www.kaggle.com/datasets/imakash3011/customer-personality-analysis.
Бумагу, которую я изначально написал для этого проекта, можно найти здесь: https://drive.google.com/file/d/19q1ZO-Kxd4iz6om46pniC5mWt4lz4us-/view
Импорт данных
Чтобы сделать проект максимально кратким, я не включил код, написанный для импорта библиотек и пакетов, используемых в этом проекте. Однако, чтобы не оставлять читателя полностью в неведении, я перечислю их здесь: numpy, pandas, datetime, matplotlib, seaborn, sklearn, scipy.
После того, как среда установлена и настроена, мы переходим к импорту вышеупомянутого набора данных и используем команду head(), чтобы проверить успешность наших операторов импорта.
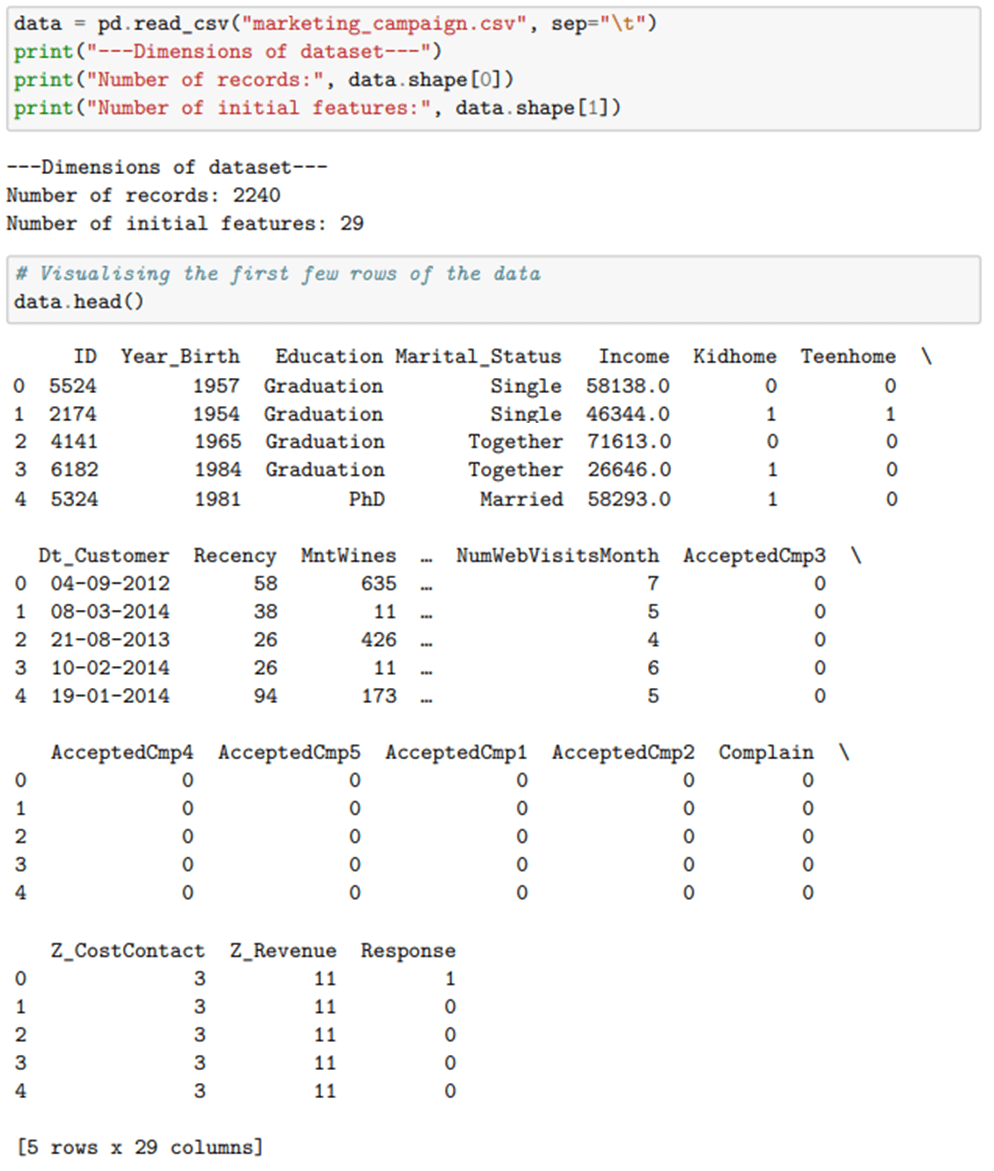
мы можем использовать функцию info(), чтобы собрать полный список функций вместе с типами данных и статусом нулевого значения.

Наблюдая за нашими чертами, мы понимаем, что каждая из них приблизительно принадлежит к одному из следующих наборов;
Люди
- ID: уникальный идентификатор для каждого клиента
- Year_Birth: год рождения клиента
- Образование: высший уровень образования, достигнутый заказчиком
- Marital_Status: состоит ли клиент в браке
- Доход: годовой доход семьи клиента (доллары)
- Kidhome: количество детей в семье клиента
- Teenhome: количество подростков в семье клиента
- Dt_customer: дата регистрации клиента в компании
- Недавность: количество дней с момента последней покупки клиента.
- Пожаловаться: если клиент подавал жалобу за последние 2 года (1=да, 0=нет)
Продукты
- MntWines: $ потрачено на вино за последние 2 года
- MntFruits: $, потраченные на фрукты за последние 2 года.
- MntMeatProducts: $, потраченных на мясо за последние 2 года.
- MntFishProducts: $, потраченные на рыбу за последние 2 года.
- MntSweetProducts: $ потрачено на сладости за последние 2 года.
- MntGoldProds: $ потрачено на изделия из золота за последние 2 года.
Продвижение
- NumDealsPurchases: количество покупок, совершенных со скидкой.
- AcceptedCmp[1–5]: принял ли клиент предложение в кампании [1–5]?
- Ответ: принял ли клиент предложение в последней кампании?
Место
- NumWebPurchases: количество покупок, совершенных через веб-сайт магазина.
- NumCatalogPurchses: количество покупок, сделанных с использованием каталога магазина.
- NumStorePurchases: количество покупок, совершенных непосредственно в магазине.
- NumWebVisitsMonth: количество посещений сайта магазина за последний месяц.
Очистка данных
В ходе оценки я выявил как минимум три проблемы, которые необходимо решить, прежде чем мы сможем приступить к разработке и реализации архитектуры нашего алгоритма. Это;
- «Доход», по-видимому, имеет небольшое количество пропущенных значений
- «Dt_Customer» — это дата, однако она представлена как объект в нашем фрейме данных (неверный тип данных)
- Существуют категориальные характеристики (Образование и Семейное положение), которые нужно будет перекодировать более интуитивно понятным образом для нашей модели.
Отсутствующие значения
Одной из распространенных практик обработки пропущенных значений является использование импутации с помощью статистического метода. Однако в этом случае, поскольку соотношение заполненных и незаполненных значений в нашем наборе данных значительно велико, мы можем просто удалить записи, в которых отсутствуют значения для этой функции, не оказывая неблагоприятного влияния на производительность наших моделей кластеризации. Это уменьшит наш набор данных на 24 с 2240 до 2216.
Изменение типа данных
Помимо решения проблемы, отмеченной вторым пунктом, я также постараюсь разработать новую функцию от Dt_Customer, которая точно скажет нам, сколько дней клиент находится в базе данных магазина. Затем приведенный ниже код преобразует функцию в тип данных datetime, а затем вычисляет новую функцию (называемую «DaysAsCustomer»), которая добавляется к нашему исходному фрейму данных.

Разработка функций и обработка категориальных функций
Данные, которые мы изначально получили, могут быть дополнены несколькими «новыми» функциями, которые создаются различными способами (на основе расчетов и/или линейных комбинаций других функций в наборе данных). Я решил создать дополнительные 6 функций. Это;
- общие расходы для каждого клиента —сумма расходов на каждый из типов продуктов
- ситуация проживания (один, с партнером) —если клиент «женат» или «вместе», то он с партнером, в противном случае он живет один
- общее количество детей — сумма детей и подростков
- общий размер семьи —сумма детей и жилищных условий (1, если один, 2, если с партнером)
- независимо от того, является ли клиент родителем —да или нет (в зависимости от созданной выше функции количества дочерних элементов)
- возраст клиента – текущий год минус год рождения клиента
Категориальные признаки необходимо перекодировать, чтобы они принимали числовые значения, что обычно требуется для того, чтобы алгоритмы машинного обучения могли их успешно интерпретировать. Чтобы решить эту проблему, мы должны сначала получить представление обо всех возможных значениях, которые может принимать каждый категориальный признак, а также о распределении значений признаков среди записей в наборе данных. Код ниже помогает нам сделать это.

Мы можем заметить еще одну проблему, особенно в функции Marital_Status — есть значения, которые не имеют для нас особого смысла (YOLO и Absurd), и значения, которые каким-то образом дублируются (Single == Alone). Мы переназначим эти значения во время разработки функций ниже.

Исследование данных
Теперь мы можем использовать функцию «описать» Pandas, чтобы получить статистическую сводку по каждой функции в нашем обновленном наборе данных. Это поможет нам в исследовательской части нашего проекта.
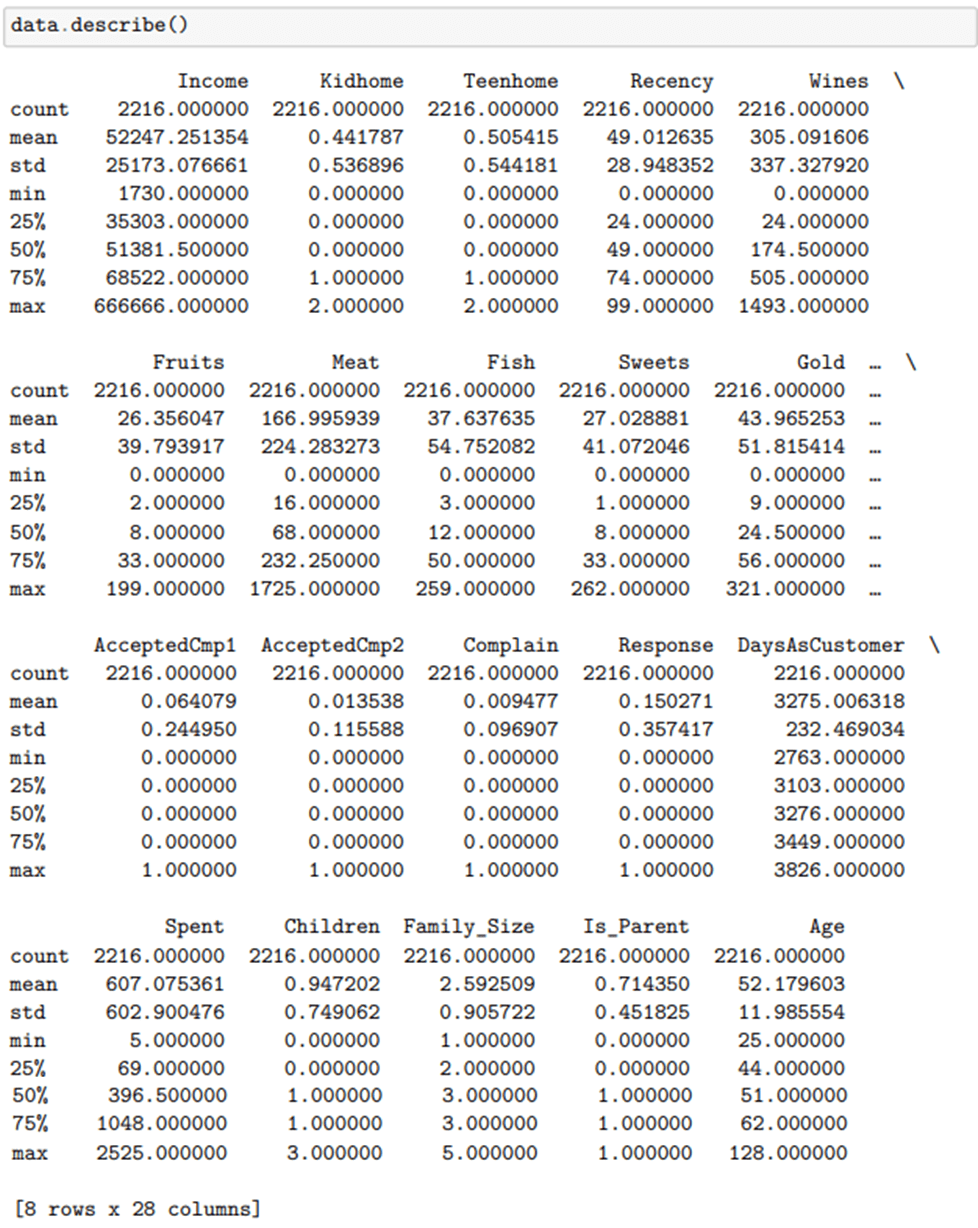
Помимо количества, среднего значения и стандартного отклонения, функция описания также дает нам сводку из 5 чисел. Он состоит из наименьшего значения (мин.), первого квартиля (25%), среднего значения (медианы), третьего квартиля (75%) и наибольшего значения (макс.) и дает нам полезное статистическое представление о каждая отдельная функция в нашем наборе данных.
При первоначальном наблюдении за вышеизложенным было выявлено несколько расхождений в данных. Во-первых, максимальное значение дохода составляет 666 666 долларов США, что является очень конкретной (и большой!) цифрой. Это может быть правильно, но можно провести дальнейший анализ, чтобы проверить значение на ощупь. Кроме того, максимальный возраст составляет 128 лет. Учитывая, что самому старому из когда-либо живших людей было «всего» 122 года, мы знаем, что это, безусловно, неверно! Эта проблема может быть связана либо с неправильным вводом/сбором данных, либо с устаревшей информацией.
Чтобы помочь нам визуализировать наши функции и то, как распределяются их значения, мы можем создавать графики данных. Здесь мы выберем подмножество функций, которые нас особенно интересуют.

Выход:
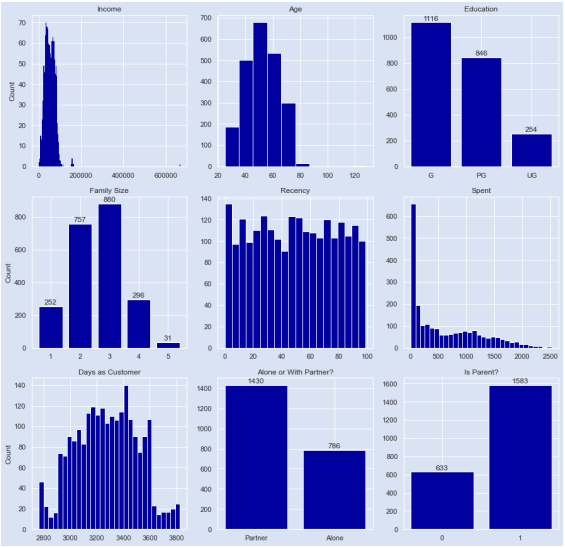
Вот сводка 2216 клиентов в нашем наборе данных, основанная на графиках, которые мы разработали выше;
- «Доход» клиентов, как правило, распределяется между 0 и 150 000 долларов США. Тем не менее, на графике выделяются несколько выбросов — есть небольшой кластер вокруг отметки в 170 000 долларов и, в частности, около отметки в 660 000 долларов. Последнее значение мы подвергали сомнению чуть ранее. Мы постараемся решить эту проблему в следующем разделе.
- График «Возраст» также выделяет выброс в наших данных — около отметки 120 лет. Остальные данные имеют тенденцию к нормальному распределению около 50-летнего возраста.
- Большинство наших клиентов получили образование на более высоком уровне (диплом и аспирантура — 89%). В то время как чуть более 1 из 10 не имеют.
- «Размер семьи» имеет небольшую положительную асимметрию и представляет собой гауссово распределение, при этом модальный размер семьи составляет 3 (880 / около 40%), за которым следует размер семьи 2 (757 / около 34%). Минимальный размер семьи — 1, а максимальный (представленный в этих данных) — 5 (в эту категорию попадает только 31 клиент).
- Переменная «Расходы» имеет форму, которую мы склонны ожидать — большое количество покупателей, не тратящих больших сумм денег (подумайте обо всех посещениях продуктовых магазинов, когда вы просто заглядываете за чем-то небольшим). Это затем имеет большой спад и медленно уменьшается по мере увеличения стоимости расходов. Вполне вероятно, что клиенты с более высокой суммой трат либо являются покупателями в течение длительного времени, либо регулярно посещают магазин. Парный график поможет нам исследовать это дальше.
- Примерно 2 из 3 клиентов (65%) живут с партнером, а остальные 35% живут одни.
- 71% клиентов в наборе данных являются родителями, 29% — нет.
Устранение выбросов
Основываясь на исследовательской задаче, выполненной выше, есть два критерия для выбросов, которые мы хотели бы удалить из нашего набора данных: те, чей доход превышает 200 000 долларов США, и / или те, чей возраст > 100 лет (оба этих пороговых значения были выбраны на основе фактических данных). . Это легко сделать с помощью следующего кода;

Наш набор данных теперь содержит 2212 клиентов.
Визуализация парных диаграмм и запуск корреляционных тестов
Мы можем использовать функцию парного графика Seaborn для построения графика парных отношений между нашими функциями. Это поможет нам, в частности, выявить любые корреляции в наших данных. Чтобы улучшить наш анализ, а также иметь одну функцию на оси x и одну на оси y, мы также будем использовать оттенок данных и метки для представления бинарной функции Is_Parent (синий для 0, оранжевый для 1), что позволяет нам для сравнения трех функций в любой момент времени. Вот код и вывод для этой работы.


Парные графики помогают нам сделать следующие выводы;
- «Доходы» и «расходы» имеют положительную корреляцию, хотя и незначительную. Выполнение теста коэффициента корреляции Пирсона даст нам одно числовое значение от -1 до 1 силы и направления этой корреляции.
- Среди визуальных элементов в последнем ряду есть общая тема, в которой «Расходы» противопоставлены «Доходу», «Давнодавности», «Дням как покупателю» и «Возрасту» — те, кто не является родителем, как правило, тратят немного больше, чем те, кто является родителем. родитель. Однако здесь следует отметить дисбаланс значений этой функции (как мы видим на самом последнем изображении) — только 29% клиентов не являются родителями. Измерение средних расходов с помощью Is_Parent поможет нам получить более точную статистику для решения этой проблемы.

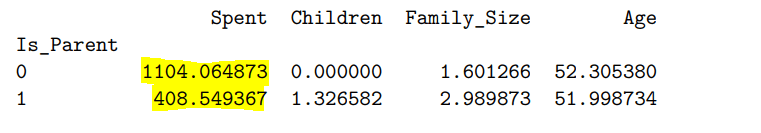


Средний средний расход для родителя составляет 408 долларов, в то время как средний средний показатель для не родителя почти втрое составляет 1104 доллара. Медианное среднее также показывает аналогичную историю: медианные расходы родителей составляют всего 198 долларов по сравнению с ошеломляющими 1188 долларами для родителей, не имеющих родителей. Помимо изображений выше, у меня также была информация о среднем и медианном доходе в зависимости от родительского статуса. Родители имели более низкий средний доход (46 471 доллар США) по сравнению с неродителями (65 677 долларов США). Эта смешанная переменная может помочь нам обосновать разницу в расходах в магазине между этими двумя типами покупателей.
Как подчеркивалось выше, следующим шагом, который мы хотели бы сделать, является построение графиков корреляции между парными признаками. Мы можем сделать это, используя функцию Pandas .corr для статистической работы, а также функцию тепловой карты Seaborn для визуальных аспектов.

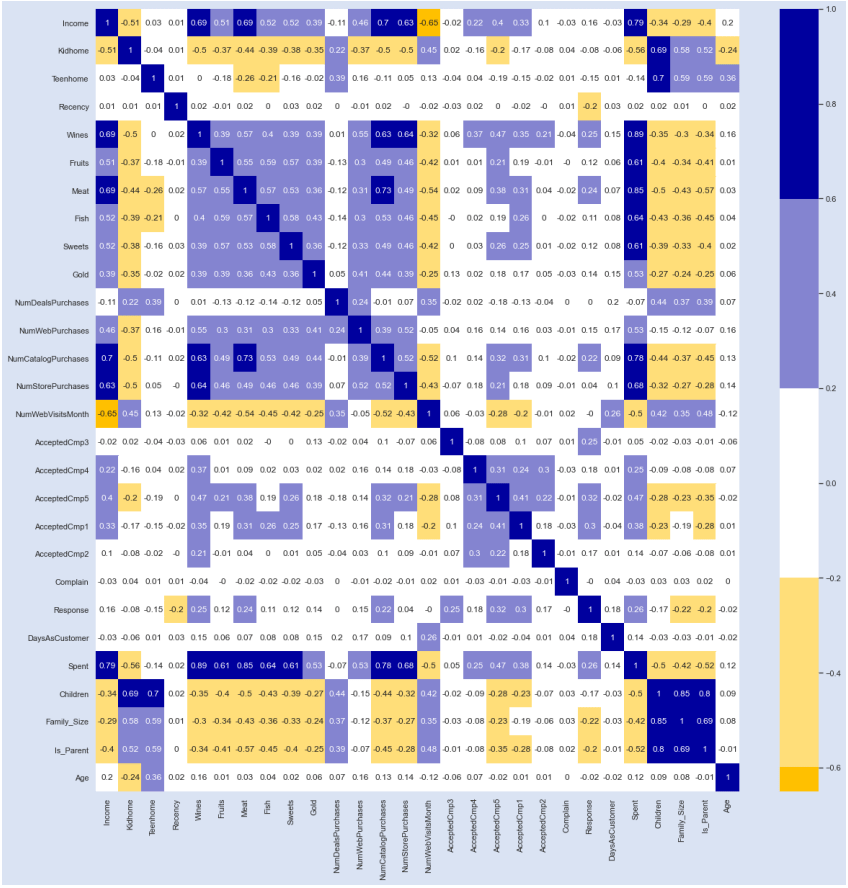
Вот краткое изложение, полученное из графика корреляции;
- Значение R для корреляции между «Доходом» и «Расходами» составляет 0,79 — довольно сильная положительная корреляция.
- «Расходы» также положительно коррелируют с 5 из 6 категорий продуктов — это имеет смысл, поскольку наша характеристика «Расходы» представляет собой линейную комбинацию этих категорий, и поэтому по мере увеличения любого отдельного компонента «Расходов» растут и общие расходы. .
- Интуитивно понятно, что «размер семьи» имеет сильную положительную корреляцию с количеством «детей» у клиента. «Is_Parent» также положительно коррелирует с «Children». Наконец, «Дом для детей» и «Дом для подростков» положительно коррелируют с количеством «детей», «размером семьи» и «является_родителем» — опять же, это звучит рационально, если учесть, как связаны эти характеристики.
- Интересно, что существует отрицательная корреляция -0,65 между «доходом» и «количеством посещений веб-сайта в месяц» — по мере увеличения дохода количество посещений веб-сайта уменьшается. Однако могут быть дополнительные смешанные переменные, не отраженные в нашем наборе данных. (помните корреляцию != причинно-следственная связь)
Предварительная обработка данных
Кодирование категориальных признаков
Давайте сначала проверим наш список категориальных функций.

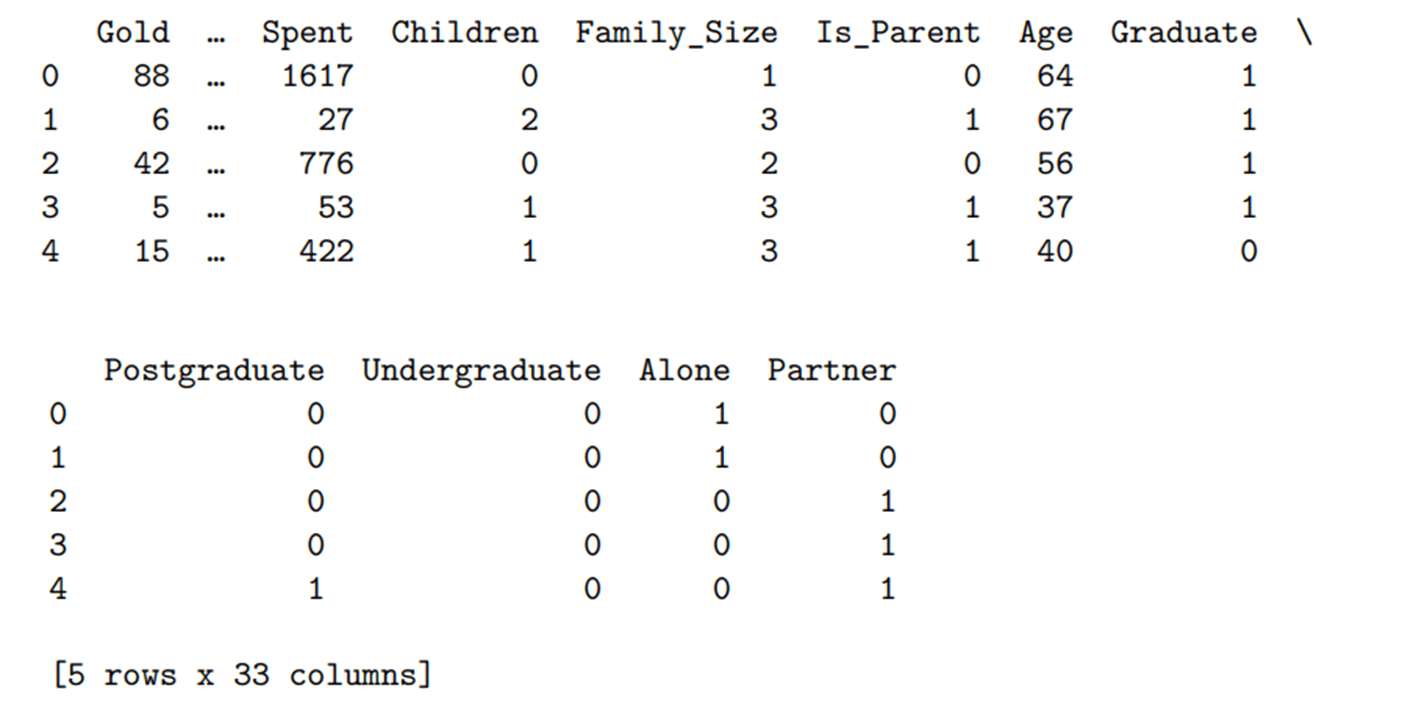
Мы будем использовать pd.get_dummies для преобразования наших категориальных значений в числовые значения, подходящие для наших алгоритмов кластеризации. Если бы это была задача прогнозирующей классификации (с наборами обучающих и тестовых данных), то One-Hot Encoding была бы более подходящей, поскольку она устраняет проблему несоответствия формы фрейма данных, если уникальные значения присутствуют только в обучающих или тестовых данных ( путем сохранения развернутых категорий в объект — подробнее здесь: https://albertum.medium.com/preprocessing-onehotencoder-vs-pandas-get-dummies-3de1f3d77dcc).

Стандартизация функций
Чтобы какая-либо одна функция не «доминировала» в обучении из-за того, что ее значения находятся в гораздо большем масштабе, чем другие, мы можем использовать методы стандартизации (удаление среднего и масштабирование до единичной дисперсии). Для этого мы будем использовать функцию StandardScaler().


Уменьшение размерности с помощью анализа главных компонентов (PCA)
PCA — это метод уменьшения размерности, который сжимает большой список признаков до гораздо меньшего списка, сохраняя при этом большую часть информации (дисперсии), присутствующей в исходном наборе данных. Это один из наиболее широко используемых методов машинного обучения, который значительно сокращает время обучения модели без существенного отрицательного влияния на производительность модели. Более подробную информацию о технических особенностях этого метода можно найти здесь — Объяснение анализа главных компонентов (АПК) | Встроенный

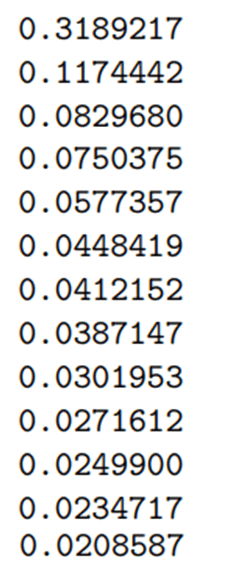
Из приведенных выше выходных данных первый основной компонент (PC) фиксирует почти 32% дисперсии в наборе данных, а второй и третий — 11% и 8% соответственно.
Всего первые 10 ПК объясняют около 82% общей дисперсии в наборе данных. Поэтому на практике может оказаться целесообразным использовать это количество. Однако в этом проекте мы хотели бы иметь возможность наглядно продемонстрировать работу и достигнутые результаты для лучшей интерпретируемости. Таким образом, мы будем использовать только первые три ПК, что позволит нам строить трехмерные графики, которые будут полезны при создании кластеров наших клиентов.

Теперь мы можем отобразить три выбранных компьютера на трехмерном графике.


Внедрение агломерационной кластеризации
Для этого проекта я решил использовать методы агломерационной кластеризации в отличие от популярной кластеризации K-средних. Одним из основных различий между этими двумя алгоритмами является наличие/отсутствие гиперпараметра «K» (количество кластеров).
В то время как стандартный алгоритм K-средних требует заранее определенного знания «K», агломерационная кластеризация этого не требует. Это связано с тем, что последний работает, стремясь построить иерархию кластеров. Он делает это, сначала рассматривая каждую запись как одноэлементный кластер. Затем пары кластеров последовательно объединяются до тех пор, пока все кластеры не будут объединены в один большой кластер, содержащий все записи. Результатом является древовидное представление, называемое «дендрограммой».
Анализ дендрограммы помогает нам выбрать оптимальное значение количества кластеров. Сначала мы вызовем функцию «связь» (алгоритм агломерационной кластеризации SciPy) и передадим ее функции «дендрограмма», чтобы построить нашу иерархическую структуру.

Интерпретация дендрограммы довольно проста — начиная снизу и работая вверх, вы можете видеть порядок, в котором кластеры были объединены, пока мы не доберемся до одного кластера, который инкапсулирует все записи в нашем наборе данных.
Вертикальные столбики наибольшей высоты указывают на самые неоднородные кластеры — они находятся далеко друг от друга геометрически. Мы можем использовать эту информацию, чтобы повлиять на количество кластеров, которые мы хотели бы определить для наших данных. Оптимальным выбором здесь будет либо 2, либо 4 кластера. Я решил использовать 4.
Теперь, когда мы решили, сколько кластеров использовать, мы можем запустить функцию Sklearn «AgglomerativeClustering» и заново построить трехмерный график сверху, но с кластерами, представленными цветами. Я построил четыре угла обзора трехмерного графика.



Крайне важно просматривать 3D-графики под разными углами, поскольку это помогает нам лучше понять распределение данных. Например, обратите внимание, как в третьем и четвертом ракурсах мы можем ясно увидеть расщепление внутри зеленого кластера. Такого разделения нет ни в одном из первых двух углов обзора из-за ориентации, в которой мы просматриваем данные.
Выявленное нами несоответствие может служить основанием для определения и включения в нашу модель пятого кластера. Однако, чтобы этот проект был компактным и лаконичным, я продолжу работу с четырьмя кластерами, которые мы определили на данный момент.
Оценка модели
Оценка модели имеет первостепенное значение для любого проекта машинного обучения. Это процесс использования различных показателей оценки для понимания производительности модели, а также ее сильных и слабых сторон.
Для большинства проектов машинного обучения она является основой для дальнейших уточнений и экспериментов специалистов по данным в поисках «лучшей» модели для своего проекта.
Для этого проекта этап оценки модели будет скорее кратким изложением нашей модели и ее производительности, а не уточнением и повторным запуском экспериментов.
Мы можем начать с рассмотрения распределения кластеров, т. е. количества записей, принадлежащих каждому кластеру.


Гистограмма выше показывает, что в кластере 1 немного больше записей, чем в трех других кластерах (740 по сравнению со средним значением для трех других кластеров, которое составляет 490).
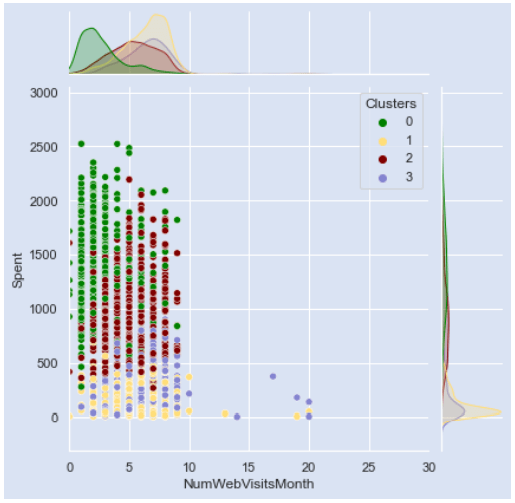
Ранее разработанная парная диаграмма и корреляционная матрица выявили линейную зависимость между признаками «Доход» и «Потрачено». Точечная диаграмма, на которой оттенок каждой точки имеет цветовую кодировку, чтобы соответствовать нашим кластерам, может (или не может!) выявить закономерности среди наших групп клиентов.


Вот краткое изложение приведенной выше диаграммы рассеяния;
- Клиенты в кластере 0, как правило, имеют немного более высокий доход, чем в других кластерах. Они также, как правило, тратят значительно больше, чем другие клиенты в этом наборе данных.
- Покупатели из кластеров 1 и 3 имеют схожие черты: доход ниже, чем у клиентов из двух других кластеров, а также они тратят меньше всего.
- Клиенты из кластера 2, как правило, тратят больше и имеют немного более высокий доход, чем клиенты из кластеров 1 и 3, но тратят меньше и имеют меньший доход, чем клиенты из кластера 0.
Информация, полученная из этой диаграммы рассеяния, может быть использована для влияния на будущие маркетинговые стратегии в этом продуктовом магазине. Например, товары с высокой стоимостью могут быть более подходящими для клиентов из кластера 0 (поскольку их доход выше, и они, как правило, тратят больше). Следующий шаг позволит нам развить это и посмотреть, сможем ли мы гарантировать, что им будут рекламироваться только товары, которые могут заинтересовать клиентов. рекламировать мясные продукты в этом сегменте.
Мы можем подробнее рассмотреть, как только «Потрачено» распределяется между этими кластерами, чтобы еще больше подтвердить предположения, сделанные в приведенном выше резюме. Для этого анализа мы можем наложить график Swarm и график Box-and-Whisker.

Дальнейшее понимание наших последних графиков;
- Мы понимаем, что у Кластера 0 самый большой диапазон денег, потраченных клиентами — от 277 до 2525 долларов. Кластер 2 следует за ним с диапазоном от 233 до 2194 долларов, хотя его межквартильный диапазон (IQR = Q3 — Q1), в котором находится 50% данных, ниже, чем у кластера 0. (528 долларов по сравнению с 615 долларами).


- Мы также можем подтвердить, что кластеры 1 и 3 инкапсулируют клиентов, которые тратят в магазине меньшие суммы. Диапазоны составляют примерно от 0 до 750 долларов для кластера 1 и 0 и 1050 долларов для кластера 3. Кроме того, их IQR также меньше (чем для кластеров 0 и 2), что говорит нам о том, что разброс данных не так велик для кластеров 1 и 2. 3.
Теперь, когда у нас есть представление как о «доходе», так и о «расходах» для нашего сегментированного набора данных, мы можем сделать еще один шаг и посмотреть, как они соотносятся с недавними маркетинговыми кампаниями/рекламными акциями, которые проводил магазин. Сначала нам нужно создать новую функцию, которая подсчитывает, сколько рекламных акций было принято для каждого клиента. Затем мы можем разделить это по нашим кластерам.


Обобщение графика подсчета для каждого кластера выглядит следующим образом;
- Кластер 0 — наши самые тратящие деньги, по-видимому, также принимают большинство рекламных акций (может быть, здесь есть какая-то корреляция!). примерно 110 (22%) этого сегмента приняли 1 промо, ~50 (10%) приняли 2 промо, ~40 (8%) приняли 3 промо и ~10 (2%) приняли целых 4 промо. Отмечается, что никто в нашем наборе данных еще не принял 5 акций — может быть, пятая еще не запущена? Наконец, примерно 270 (55%) из этих клиентов не приняли ни одной акции — график показывает нам, что в целом большинство людей не принимали участия ни в каких акциях, независимо от их членства в кластере — может ли магазин работать над улучшением этого?
- Кластеры 1 и 3 демонстрируют схожее поведение в том смысле, что у них обоих большая доля клиентов, не принявших ни одной рекламной акции (около 91% для Кластера 1 и 88% для Кластера 3). Кроме того, гораздо меньшая часть клиентов в этих кластерах согласилась только на одну акцию. Начиная с 2 рекламных акций, цифры незначительны.
- Кластер 2 имеет хорошее сочетание баров. Около 400 (75%) клиентов не приняли ни одной акции, 90 (16%) или около того приняли одну, около 30 (5%) приняли 2, а остальные делятся между 3 и 4 акциями.
Теперь мы можем сосредоточить внимание на количестве покупок, совершенных со скидкой:


- Наши самые большие траты, Кластер 0, как правило, вообще не используют много купонов на скидку. 50% клиентов в этом кластере использовали от 0 до 2 ваучеров. Есть несколько исключений, когда клиенты в этом кластере использовали 4, 6 и 15 ваучеров.
- Как и в случае с приведенными выше данными об акциях, Кластеры 1 и 3 имеют схожее поведение — оба они имеют медианы 2 и IQR между 1 и 3. Клиенты Кластера 3 немного чаще используют больше ваучеров, чем Кластер 1, из-за более длинных усов на сюжет.
- Кластер 2 имеет медиану из 3 ваучеров и IQR от 2 до 4. Эти данные имеют гораздо более высокую дисперсию, чем три других кластера, где всего 2 выброса появляются на 0 и 15. Диапазон для этого кластера составляет 12.
Наш следующий набор визуализаций будет посвящен каналам покупок, которые используют наши клиенты. Мы построим совместный график для каждой из «покупок в Интернете», «покупок каталога», «покупок в магазине» и «посещений сети». Здесь важно отметить, что «Веб-покупки» и «Веб-посещения» — это две совершенно разные функции. Здесь может быть возможность сравнить две функции друг с другом и разработать показатели конверсии/коэффициента транзакций, если это будет интересно магазину.

Покупки на веб-сайте x расходы

Покупки каталога x расходы

Покупки в магазине x Расходы

Посещения веб-сайта x расходы
Профилирование клиентов
Этот раздел, пожалуй, самый ценный для бизнеса. Каждый предыдущий раздел так же важен, но именно здесь мы действительно можем рассказать историю с помощью данных, создав профили клиентов, помогая нам понять их поведение и отношение. Благодаря этому мы можем повлиять на будущие маркетинговые стратегии и, надеюсь, улучшить взаимодействие и, в конечном итоге, продажи и доходы.
Здесь мы по-прежнему сосредоточимся на нашей функции «Потрачено», но мы сопоставим ее с некоторыми более личными функциями в нашем наборе данных.
Детский дом x Потрачено

Подростки дома х провел

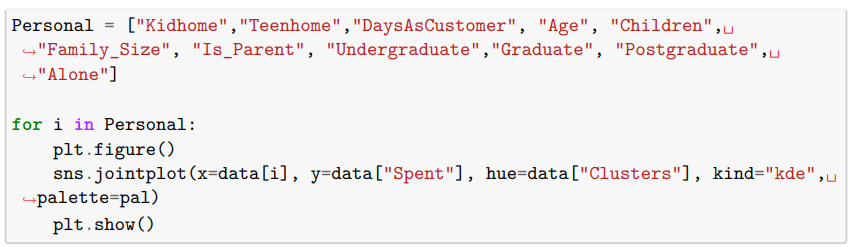
Количество дней как клиент x потрачено
Возраст x Потрачено

# детей х потрачено

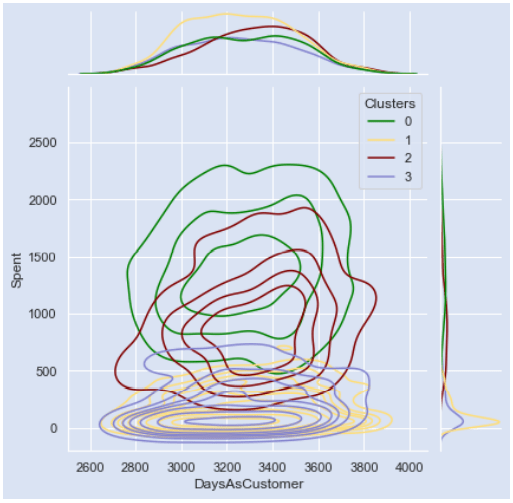
Размер семьи x потрачено
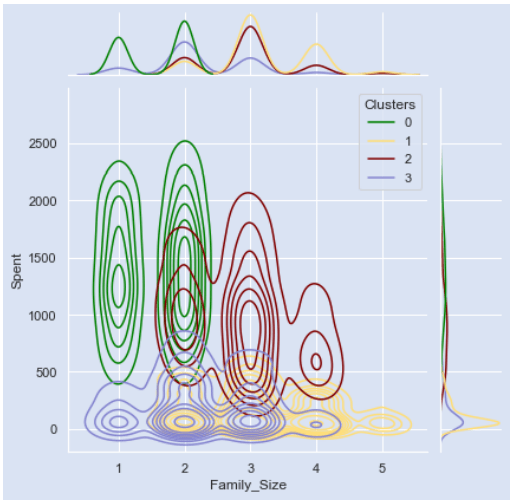
Родитель? х Потрачено
Бакалавриат? х Потрачено
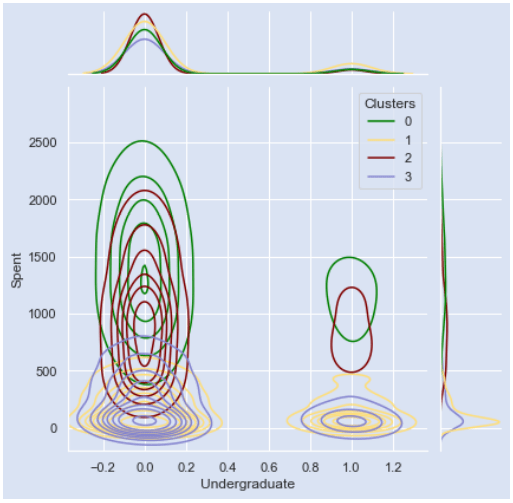
Выпускник? х Потрачено

Аспирантура? х Потрачено

Живет один? х Потрачено
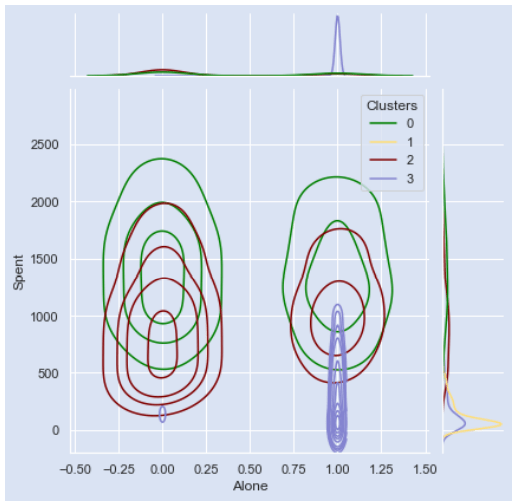
Вот профили клиентов, которые можно почерпнуть из работы, которую мы проделали в этом проекте;

Резюме и выводы
В этом проекте мы продемонстрировали как фундаментальные, так и передовые методы в науке о данных. Подготовка и очистка данных позволили нам работать с гораздо более надежным и интуитивно понятным набором данных. Анализ данных помог нам понять особенности данных со статистической и аналитической точек зрения. Кластеризация позволила нам выявить в нашем наборе данных потенциальные сегменты клиентов, на которых мы можем ориентироваться, а оценка и профилирование дали нам возможность объединить всю предыдущую работу и сделать выводы.
Нравится этот контент? Пожалуйста, рассмотрите возможность подписаться на меня и поделиться историей! Пожалуйста, оставьте любые вопросы или комментарии ниже, и я свяжусь с вами. Спасибо, хорошего дня :)
Свяжитесь со мной в LinkedIn: https://www.linkedin.com/in/thomas-staite-msc-bsc-ambcs-55474015a/






