
В последнее время искусственный интеллект все чаще применяется в бизнесе и повседневной жизни, особенно в сферах финансов, здравоохранения, управления персоналом, музыки и издательского дела (ссылка). Успех искусственного интеллекта в этих областях во многом обусловлен новыми инновационными решениями искусственного интеллекта для решения реальных проблем.
Чтобы помочь вам быть в курсе последних тенденций в области решений искусственного интеллекта, мы в AI Network работаем над серией сообщений в блогах под названием Современные решения на основе искусственного интеллекта. Сегодня, в первом посте серии, мы будем говорить о BERT (представления двунаправленного кодировщика от Transformers), языковой модели искусственного интеллекта на базе Google, которая недавно привлекла внимание общественности, демонстрируя лучшую точность, чем у людей, в некоторых оценках производительности (« ссылка").
Команда разработчиков BERT впервые опубликовала свою оригинальную статью 11 октября 2018 года. Примерно через три недели они выпустили свой исходный код и предварительно обученную модель, как и было обещано (ссылка). Интересно, что и разработчики НЛП, и исследователи в одинаковой степени выразили восхищение и озабоченность по поводу первоначального исследования BERT.
В то время как потрясающие показатели производительности BERT вызывали ажиотаж, BERT также вызвал беспокойство в сообществе НЛП из-за нетрадиционного подхода команды разработчиков BERT. В то время как в традиционных моделях НЛП приоритет отдается гибкости или производительности, команда разработчиков BERT использовала архитектуру модели общего назначения и универсальные обучающие данные, которые повысили как производительность, так и гибкость одновременно. Они достигли этого. вложив в свою модель как можно больше машинных ресурсов. Казалось, что для достижения производительности на уровне BERT тем, кто изучает языковые модели искусственного интеллекта, естественным образом придется пересмотреть свой подход и пересмотреть то, как настроить свою исследовательскую среду.
В этой статье мы кратко рассмотрим подходы, идеи и результаты оценки производительности BERT. Мы также рассмотрим, какие сообщения эти результаты отправляют сообществу разработчиков естественного языка и ИИ-разработчикам и как это соотносится с AI Network.
Что за решение BERT?
Подход
Подход разработчиков BERT, который можно прочитать в этой статье (ссылка) и в этой публикации Reddit (ссылка), можно резюмировать как (1) разработка универсального решения, (2) масштабируемая реализация и (3) построение моделей с максимально возможным количеством машинных ресурсов для максимальной производительности.
В статье BERT для оценки производительности использовалось 11 задач НЛП. Во всех задачах использовалась только одна предварительно обученная модель. Это отклоняется от общепринятой практики до BERT, когда модели для конкретных задач создавались для каждой задачи. Вместо этого перед выполнением каждой новой задачи к предварительно обученной модели BERT применялась тонкая настройка.
Архитектура модели группы BERT основана на Transformer, который представляет собой архитектуру универсального модуля глубокого обучения, выпущенную Google в 2017 году. Одним из самых больших преимуществ использования Transformer является повышенная скорость обучения, которая достигается за счет параллельной обработки ( "ссылка"). Размеры моделей BERT, использованных в статье, были следующими:
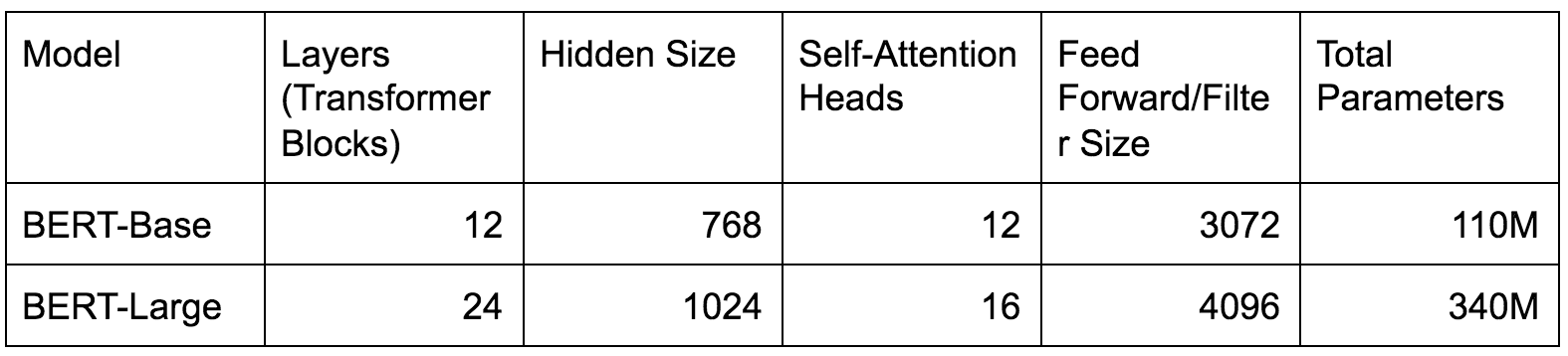
ИНС с сотнями миллионов (110M, 340M) параметров огромна по сравнению с другими популярными решениями. Чтобы поместить эти числа в контекст, сеть политик AlphaGo (ссылка) имеет около 4,6 млн параметров, а ResNet-50 (ссылка), популярная ИНС для распознавания изображений, как известно, состоит из около 25 млн параметров.
В архитектуре модели BERT они использовали два хорошо известных универсальных корпуса в качестве данных для предварительного обучения: BooksCorpus (800 млн слов) и английскую Википедию (2500 млн слов). Если бы данные, относящиеся к конкретной задаче, использовались для каждой задачи, мы могли бы ожидать гораздо лучших результатов, чем те, которые опубликованы в статье.
Размер используемых машинных ресурсов будет обсуждаться далее в разделе Источник и ресурс.
* Материал, представленный в этой статье, в основном относится к статьям BERT (ссылка) и сообщениям Reddit (ссылка), включая рисунки и таблицы. Для получения дополнительной информации обратитесь к исходным текстам.
Ключевая особенность
Двунаправленная модель
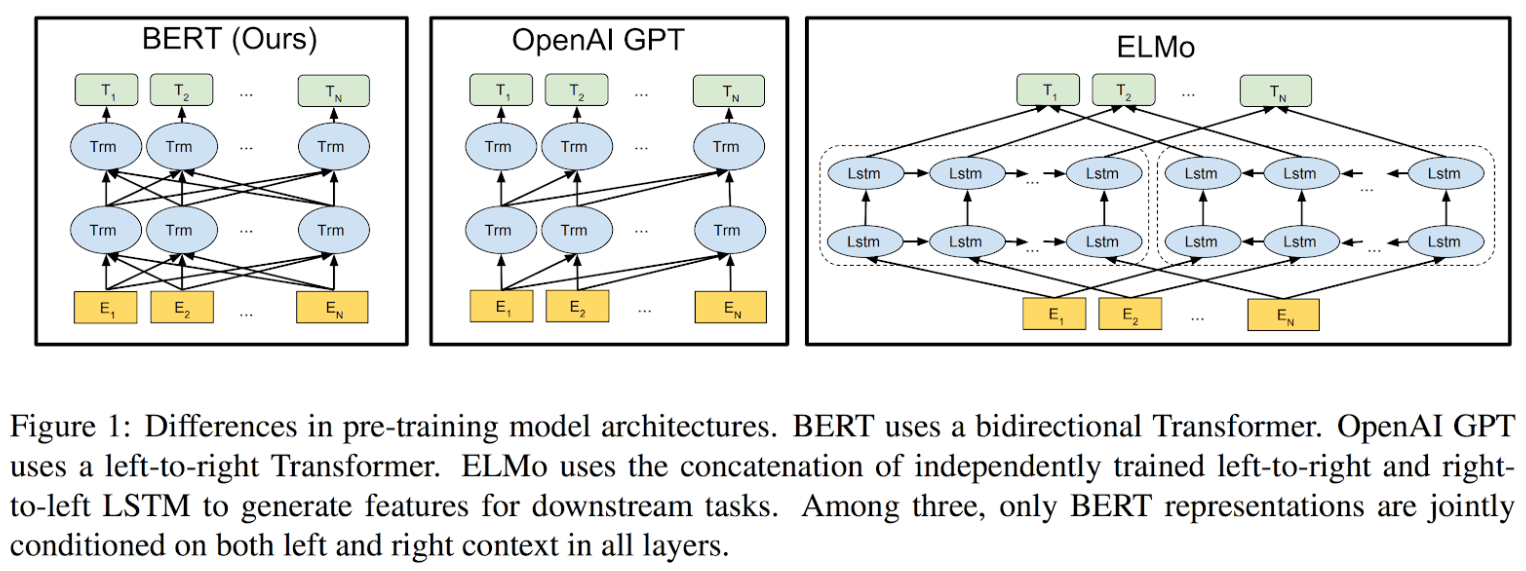
На рис. 1 (отрывок из статьи) показаны архитектуры модели предварительного обучения, используемые в BERT, OpenAI GPT и ELMo. В то время как OpenAI GPT использует преобразователь слева направо, а ELMo использует в комбинации независимые модели слева направо и справа налево, BERT использует единую двунаправленную модель, которая одновременно видит и левый, и правый контексты.
Маскированный LM

Если бы использовалась только глубокая двунаправленная модель, описанная выше, был бы риск создания циклов внутри модели, что сделало бы само обучение бессмысленным. Как правило, когда количество скрытых слоев в нейронной сети больше, чем количество входных параметров, полученный результат, вероятно, станет функцией идентификации, то есть модель выводит те же значения, что и входные значения. Чтобы решить эту проблему, разработчики BERT разработали метод под названием Masked LM (см. Рис. 2), который использует автоэнкодеры с шумоподавлением для преднамеренного искажения входных данных (ссылка). То есть слово выбирается случайным образом из массива входных слов, заменяется на [MASK] с вероятностью 80%, заменяется случайным словом с вероятностью 10% или используется без изменения с оставшейся вероятностью 10%.
Прогнозирование следующего предложения

Многие из задач, используемых для оценки эффективности, должны понимать отношения между предложениями. Таким образом, разработчики BERT использовали модели, способные предсказывать такие отношения между предложениями. Как показано на рис. 3, предложения были извлечены из одноязычного корпуса, помечены IsNext, если пары предложений действительно были связаны, и помечены NotNext в противном случае.
Оценка эффективности
КЛЕЙ
Набор данных GLUE (General Language Understanding Evaluation) представляет собой набор различных задач обработки естественного языка, предназначенных для объективного сравнения и оценки решений обработки естественного языка.

В таблице 1 (отрывок из статьи) приведены результаты оценки набора данных GLUE. Таким образом, BERT-Base и BERT-Large показали лучшие результаты, чем самые известные решения по всем задачам, улучшив среднюю производительность на 4,4% и 6,7% соответственно.
Отряд
Набор данных ответов на постоянный вопрос (SQuAD) состоит из более чем 100 тысяч пар вопросов / ответов, полученных на основе краудсорсинга. По заданному абзацу и набору вопросов задача состоит в том, чтобы найти ответы из сегментов абзаца, соответствующих вопросам.

В таблице 2 (отрывок из статьи) приведены результаты оценки для SQuAD. Таким образом, BERT показал результаты, превосходящие самые известные системы как в ансамблевой, так и в одиночной среде. BERT также превзошел людей.
CoNLL-2003
Набор данных CoNLL-2003 состоит из 200 тыс. Обучающих слов, каждое из которых снабжено примечаниями «Человек», «Организация», «Местоположение», «Разное» или «Другое» (безымянный объект).

В таблице 3 (отрывок из статьи) приведены результаты CoNLL-2003. Как видите, BERT-Large показал лучшие результаты, чем другие системы.
РАСКАЧИВАТЬСЯ
Набор данных «Ситуации со состязательными поколениями» (SWAG) состоит из 113 тыс. «Проблем создания пар предложений». Задача состоит в том, чтобы выбрать наиболее естественное предложение из четырех вариантов, следующих за исходным предложением.

В таблице 4 (отрывок из бумаги) показаны результаты оценки для набора данных SWAG. Результаты показывают, что BERT-Large улучшает производительность ESIM + ELMo на 27,1%. BERT-Large также превзошел человеческих экспертов.
Шаги обучения и производительность
Чтобы увидеть, как шаги обучения влияют на производительность, команда разработчиков BERT сравнила производительность при различном количестве шагов обучения, используя модель BERT-Base на основе архитектуры Masked LM и Left-to-Right соответственно.

На приведенном выше графике (отрывок из статьи) показаны их выводы. Последствия этого эксперимента можно резюмировать следующим образом:
- Вопрос: Действительно ли BERT требуется такой большой объем предварительной подготовки (128 000 слов / пакет * 1 000 000 шагов) для достижения высокой точности точной настройки?
Ответ: Да (как видите в графе сходимости). - Вопрос: Предварительное обучение модели машинного обучения с маской сходится медленнее, чем предварительное обучение модели слева направо?
Ответ: Да (см. График). Однако с точки зрения абсолютной производительности Masked LM всегда превосходил модель слева направо, за исключением начала.
Источник и ресурс
Команда разработчиков BERT сообщила, что для завершения предварительного обучения модели потребовалось около четырех дней. Технические характеристики машины, которую они использовали, следующие:
- BERT-Base: 4 облачных TPU (всего 16 чипов TPU)
- BERT-Large: 16 облачных TPU (всего 64 чипа TPU)
Это огромное количество оборудования, и команда BERT утверждает, что на предварительное обучение могло бы потребоваться больше года, если бы они использовали только графические процессоры, такие как TESLA P100.
Как упоминалось ранее, основная философия разработчиков BERT:
- разработка универсального решения
- масштабируемая реализация
- построение моделей с максимально возможным количеством машинных ресурсов для повышения производительности.
Успех этого подхода предполагает один важный сдвиг в области исследований и разработок НЛП - разработка решений искусственного интеллекта НЛП больше не принадлежит экспертам по НЛП. Вместо этого теперь он открыт для всех, кто обладает соответствующими навыками программирования и способностями к управлению машинными ресурсами.
Еще один заслуживающий внимания момент заключается в том, что положительная взаимосвязь между размером модели (или количеством ресурсов) и производительностью, которая легко заметна по разнице в производительности между BERT-Base и BERT-Large, указывает на растущую зависимость решений ИИ от машинных ресурсов. Эта повышенная зависимость от постоянно увеличивающихся машинных ресурсов станет еще более критичной для конкурентоспособности исследовательских организаций и компаний в будущем.
Как упоминалось ранее, поскольку команда разработчиков BERT уже опубликовала свой исходный код и предварительно обученную модель (ссылка), любой желающий теперь может использовать BERT. Однако это не означает, что каждый может обучить новую модель BERT; Это могут сделать только те, у кого есть соответствующие ресурсы.
Именно здесь AI Network хотела бы внести свой вклад. Конечная цель AI Network состоит в том, чтобы (1) предоставить всем заинтересованным рентабельные ресурсы и (2) предоставить платформу (также известную как Open Resource Platform) для таких сервисов, которые соединяют исходный код пользователя с хорошо приспособленными средами выполнения. Для более подробного ознакомления с Open Resource прочтите следующий пост:
- Что такое Open Resource и зачем он нужен? (Вы можете попробовать запустить BERT онлайн бесплатно)
На этом сегодняшняя публикация. Надеюсь, ты следи за обновлениями этого канала. Спасибо.
Ссылки
- Https://en.wikipedia.org/wiki/Applications_of_artificial_intelligence
- Лучшая модель НЛП когда-либо? Google BERT устанавливает новые стандарты для 11 языковых задач
- BERT: предварительная подготовка глубоких двунаправленных преобразователей для понимания языка
- Https://github.com/google-research/bert
- BERT (публикация на Reddit)
- Трансформер: новая архитектура нейронной сети для понимания языков
- Иллюстрированный трансформер
- Искусственный интеллект как структурная оценка: экономические интерпретации Deep Blue, Bonanza и AlphaGo
- ResNet-50 обучен на данных соревнований ImageNet






