Обработка естественного языка | Предварительная обработка текста
Обновленная версия этой статьи перемещена на мой сайт.
В сегодняшнем выпуске 📺:
- Так что же такое токенизация?
- А что такое токен?
- Почему мы токенизируем?
- Типы токенизации
- Несколько слов о лингвистике!
- Как токенизировать?
- Текстовый корпус
- Токенизация с помощью функции `split()`
- Токенизация с помощью NLTK
- Токенизация с помощью spaCy
- Как токенизация происходит под капотом в spaCy
- В заключение
🤖 TLDR:
Если вы хотите сразу перейти к сути, перейдите к разделу Токенизация с помощью spaCy.
В прошлой статье мы кратко обсудили, что такое НЛП, как оно используется в отрасли и как оно влияет на нашу повседневную жизнь.
Мы также прошли конвейер НЛП и различные его этапы. Мы видели, что предварительная обработка текста является важным блоком в конвейере. После получения данных мы применяем ряд шагов предварительной обработки, чтобы подготовить их к моделированию.
Одним из первых шагов в предварительной обработке текста является Токенизация.
Так что же такое токенизация?
Токенизация — это процесс создания токенов.
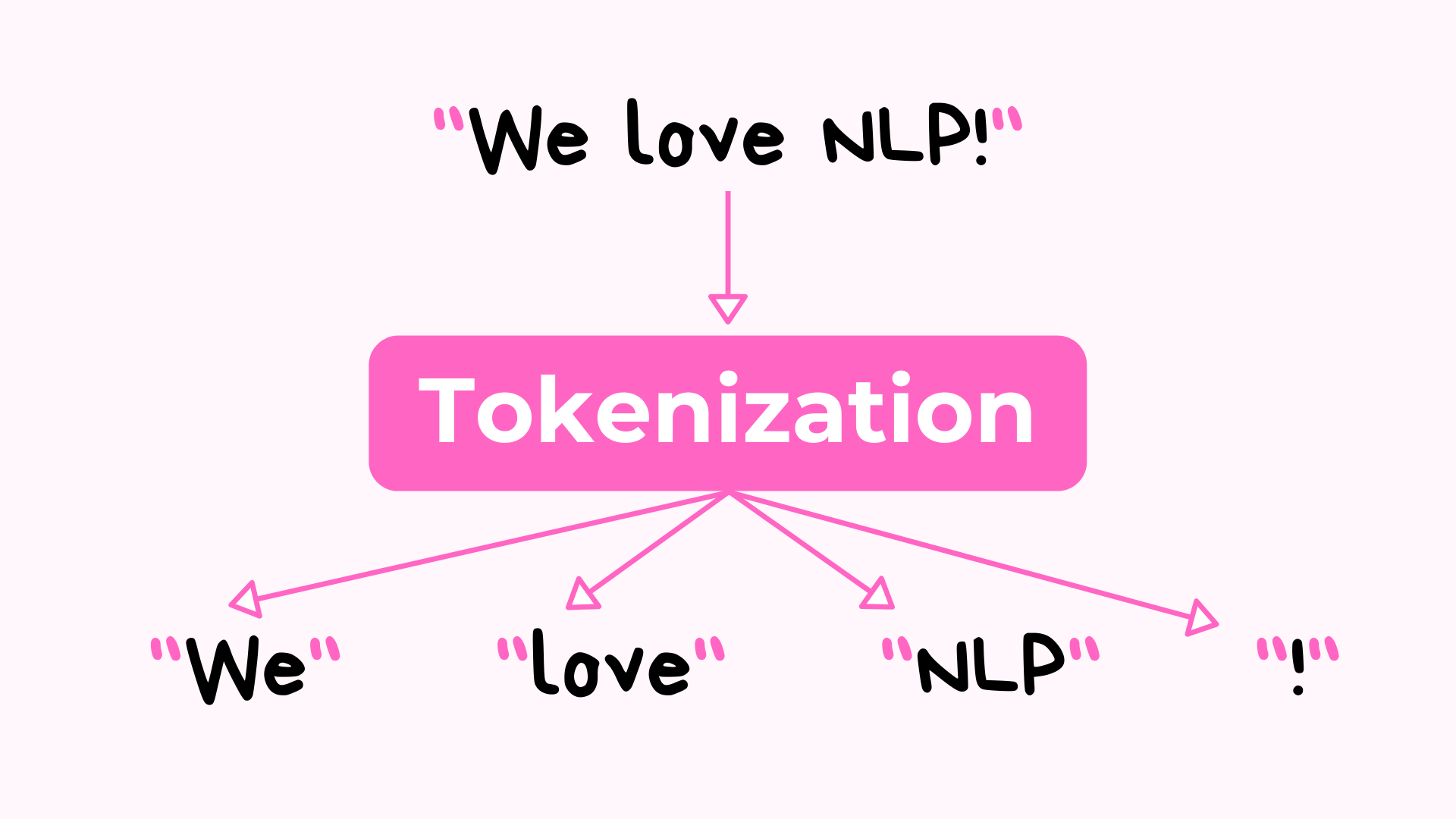
А что такое токен?
Токены можно рассматривать как структурную единицу текстовой последовательности (данных).
Строка строится путем объединения разных символов. Персонажи собираются вместе, чтобы составить слово. Затем многие слова объединяются в предложение, а предложения образуют абзац. Многие абзацы образуют документ и так далее.
Эти единицы, из которых состоит корпус текста, называются лексемами, а процесс разделения текстовой последовательности на ее маркеры называется маркировкой.
Как объяснялось выше, эти токены могут быть:
- персонажи
- слова (отдельные слова или наборы из нескольких слов вместе)
- часть слов
- знаки препинания
- предложения
- обычные выражения
- специальные жетоны (мы обсудим их в ближайшем обсуждении)
Почему мы токенизируем?
Это законный вопрос. Мы знаем, что такое токенизация, но зачем нам это делать? Как это помогает в нашей задаче НЛП?
Как мы поняли, токены — это строительные блоки текста на естественном языке. Поэтому большая часть предварительной обработки и моделирования происходит на уровне токенов.
Например, удаление стоп-слов, поиск корней, лемматизация и многие другие этапы предварительной обработки происходят на уровне токенов (мы узнаем о них в следующих обсуждениях).
Даже архитектуры нейронных сетей обрабатывают отдельные токены, чтобы понять смысл документа. Иллюстрация ниже объясняет это в действии.

💡 Мы углубимся в RNN и другие приложения глубокого обучения для НЛП в предстоящих обсуждениях.
Типы токенизации
Как мы теперь знаем, Токенизация помогает разделить исходный текст на символы, слова, предложения и т. д. в зависимости от решаемой проблемы.
- Поэтому, если вы разбиваете текстовые данные (или документ) на слова, это называется Токенизация Word.
- Если документ разбит на предложения, то это называется Токенизация предложений.
- Точно так же разделение документа на отдельные символы называется токенизацией символов.
so on …
Несколько слов о лингвистике!
Как вы уже знаете, НЛП в значительной степени включает в себя изучение человеческого языка или лингвистики. Поэтому давайте быстро освежим понятие префиксов, суффиксов и инфиксов, прежде чем продолжить.
- Префикс: символы в начале.
Пример: $, (, “ - Суффикс: символы в конце.
Пример: км, ), !, ? - Инфикс: символы между ними.
Пример: -, _, /, … - Исключение: специальные записи, в которых требуется определенный уровень знаний и интеллекта, чтобы решить, следует ли разделить знаки препинания или нет.
Пример: США, США, США, доктор, давайте
В следующих разделах мы увидим множество примеров, которые еще больше прояснят эти концепции.
Как токенизировать?
Итак, мы поняли, что такое токенизация и почему она полезна, давайте теперь разберемся, как токенизировать заданный текстовый корпус в Python.
Существует несколько способов токенизации данной текстовой последовательности, и разные библиотеки предлагают для этого несколько методов и функций. Давайте рассмотрим несколько.
Давайте кодировать! 🚀
Текстовый корпус
В качестве текстового корпуса для этого упражнения мы возьмем популярный твит Навала Равиканта.
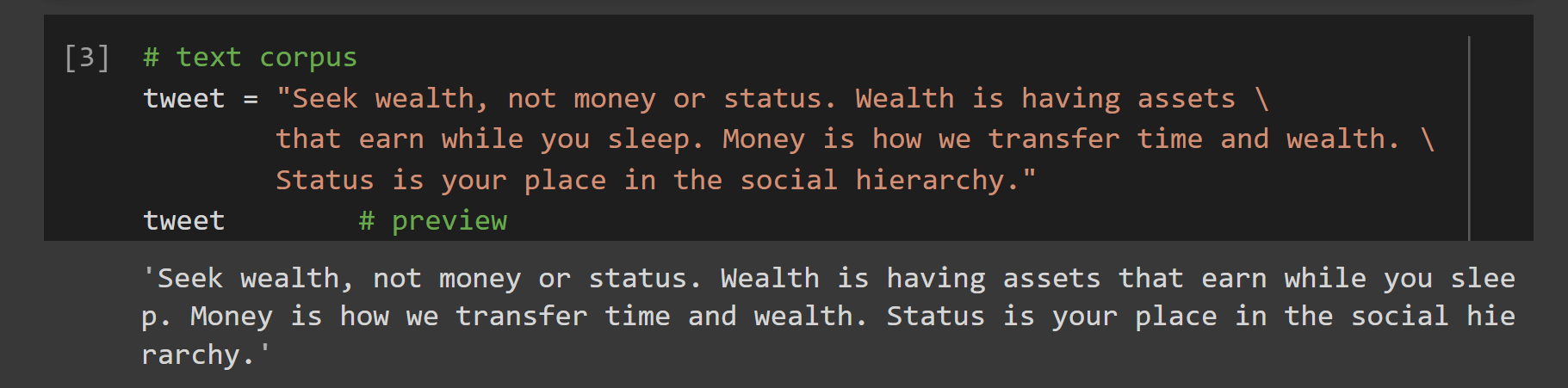
Давайте также возьмем другой текстовый корпус, в котором задействовано немного больше сложностей.

В то время как в первом корпусе мало обычных предложений, во втором корпусе есть некоторые сложные детали, такие как аббревиатуры, имена дескрипторов социальных сетей, электронная почта, веб-сайт, смайлики и многое другое.
Давайте посмотрим, как работает каждый из методов токенизации для каждого имеющегося корпуса.
Токенизация с помощью функции `split()`
Один из самых ранних способов разбить текст на токены — использовать функцию split().
Токенизация Word
По умолчанию функция split() «разбивает» текст на части по пробельным символам.
🔍 Наблюдения:
- Мы можем заметить, что он хорошо справляется с разделением текста на отдельные слова.
- Однако знаки препинания не отделялись от слова, например: «статус» и «нас!».
- Также обратите внимание, что такие префиксы, как "$", не отделены от токена в "$10".
Токенизация предложения
Давайте попробуем разбить корпус на точки.

🔍 Наблюдения:
- Все фразы разделены. Однако, за исключением 1-го предложения, все остальные предложения имеют лишние пробелы в начале предложения.
- Кроме того, список предложений также имеет пустое предложение в конце.

🔍 Наблюдения:
- Мы ясно видим, что функция split() плохо справляется с разделением текста на предложения.
- США были разделены на разные предложения вместе с URL-адресом и адресом электронной почты.
Нам явно нужно лучшее решение! Давайте теперь рассмотрим некоторые другие библиотеки, которые лучше справятся с токенизацией.
Токенизация с помощью NLTK
NLTK — популярная библиотека НЛП. Он предлагает несколько отличных встроенных токенизаторов, давайте изучим.

Токенизация слов
NLTK предлагает множество различных методов токенизации слов. Мы изучим следующее:
- word_tokenize()
- TreebankWordTokenizer
- WordPunctTokenizer
- регулярное выражение
Давайте пройдемся по ним один за другим.
1. word_tokenize()
🔍 Наблюдения:
- word_tokenize() хорошо справляется с токенизацией отдельных слов, а также знаков препинания.
Давайте посмотрим на некоторые другие альтернативные токенизаторы слов, которые предлагает NLTK.
2. Токенизатор TreebankWord
🔍 Наблюдения:
- Когда мы внимательно наблюдаем, мы можем заметить, что хотя знаки препинания, такие как «,» были преобразованы в токены. Но “.” остаться без изменений со словами, например "status" и "sleep".
На самом деле это не хорошо или плохо. Все зависит от контекста проблемы, которую мы пытаемся решить.
Давайте продолжим работу с другим токенизатором NLTK.
3. WordPunctTokenizer
🔍 Наблюдения:
- также созданы правильные токены слов с отдельными токенами для знаков препинания.
4. Регулярное выражение
NLTK также предлагает несколько методов токенизации текстовых последовательностей с помощью регулярных выражений.
🔍 Наблюдения:
- Токенизаторы RegEx исключают пунктуацию.
Токенизация предложения
Токенизация предложений — это процесс разделения корпуса текста на разные предложения.
NLTK также предлагает несколько различных методов токенизации предложений. Мы изучим следующее:
- send_tokenize()
- PunktSentenceTokenizer
- Токенизация предложений в тексте на испанском языке
Давайте кодировать! 🚀


🔍 Наблюдения:
- Обе текстовые последовательности были успешно преобразованы в разные предложения.
- В отличие от метода split(“.”), здесь лишние пробелы и пустые предложения автоматически обрезаются, и мы получаем чистые предложения.
Альтернативный метод от NLTK для токенизации предложений выглядит следующим образом.
2. Токенизатор PunktSentenceTokenizer
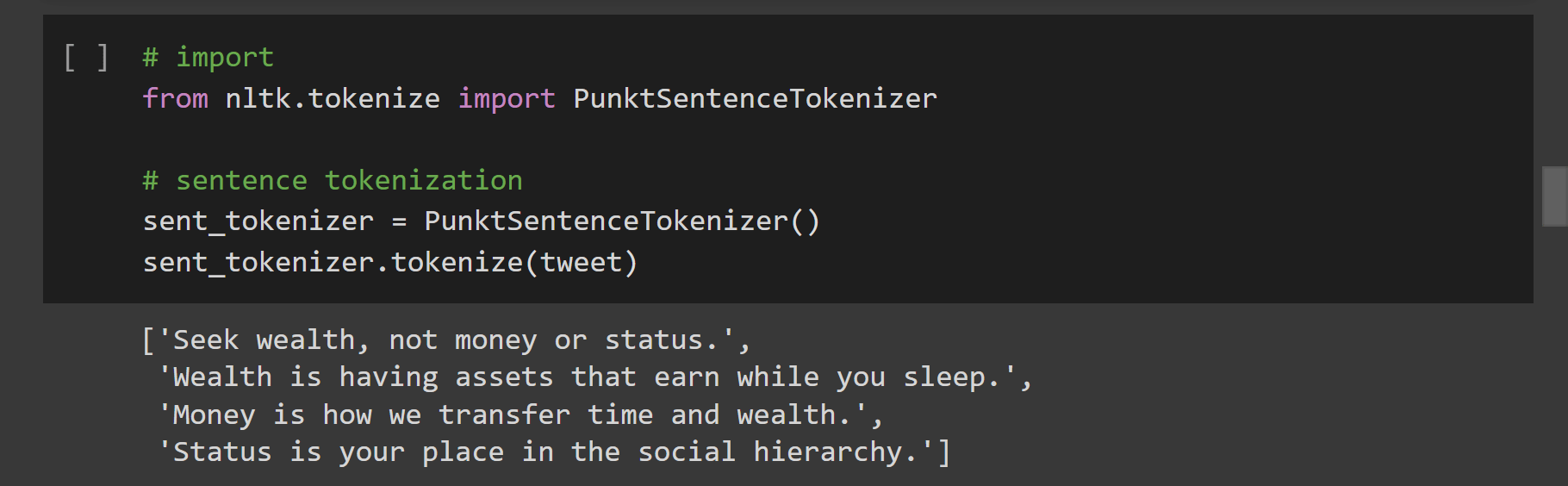
В то время как корпус здесь был разделен на 4 разных предложения в качестве токенов. Однако давайте посмотрим, работает ли он так же со сложной текстовой последовательностью.

🔍 Наблюдения:
- PunktSentenceTokenizerразбил корпус текста на 5 разных предложений на основе многократного появления знаков препинания.
Поэтому вам следует помнить об этом.
3. Токенизация предложений в испанском тексте [Бонусный раздел🤑]
Большая часть работы НЛП сегодня выполняется для английского языка. Итак, вот кое-что для тех, кто интересуется НЛП для разных языков.
NLTK также предлагает методы токенизации для разных языков. Один из таких примеров приведен ниже.

Краткое содержание
Несмотря на то, что NLTK предлагает несколько различных токенизаторов для одной и той же задачи, наиболее популярными и эффективными токенизаторами от NLTK являютсяword_tokenize()иsent_tokenize. ().
🔍 Наблюдения:
В то время как NLTK хорошо справляется с токенизацией. Однако мы можем наблюдать и некоторые недостатки, когда NLTK не смог обработать некоторые исключения.
- Он отделял «@» от имени дескриптора Twitter.
- Он разделил URL-адрес на 3 разных токена: "https", ":", "//"www.example.com/"". .
Токенизация с помощью spaCy
В этом разделе мы обсудим:
- Токенизация слов
- Токены неизменны
- Токенизация предложения
- Визуализация токенов и сущностей
Мы заметили, что, хотя NLTK предлагает несколько хороших токенизаторов, у библиотеки spaCy есть некоторые недостатки, которые она преодолевает.
Кроме того, токенизировать с помощью spaCy намного проще. Посмотрим, как!


Токенизация слов
Благодаря внутренней работе конвейера spaCy токены автоматически создаются объектом doc.
🔍 Наблюдения:
- Вызов токенов — это всего лишь одна строка кода с помощью spaCy.
- Поскольку объект doc представляет собой набор всех токенов, поэтому длина объекта doc напрямую дает нам количество токенов в корпусе.
Давайте токенизируем другой корпус, который у нас есть.
🔍 Наблюдения:
- spaCy очень точно разбивает текст на токены, включая префиксы, суффиксы, инфиксы, знаки препинания и исключения.
- Он знает, что такое дескриптор Twitter, поэтому не отделяет “@” от имени дескриптора.
- Точно так же он распознает полный URL-адрес веб-сайта, поэтому успешно сохраняет его полностью.
spaCy обрабатывает все это (и многое другое) «под капотом» и предоставляет нам токены всего в 1 строке кода.
Токены неизменны
В то время как маркеры приводят к списку, а элементы списка могут быть изменены в Python, однако маркеры не могут быть изменены.
🔍 Наблюдения:
- Ошибка (TypeError: объект «spacy.tokens.doc.Doc» не поддерживает назначение элементов) говорит нам, что токены неизменяемы. И это имеет смысл, поскольку изменение токенов приведет к изменению исходного набора данных.
Токенизация предложения
Токенизация предложений также проста, как токенизация Word с помощью spaCy.
Объект doc.sents дает нам токены предложения. Посмотрим, как!

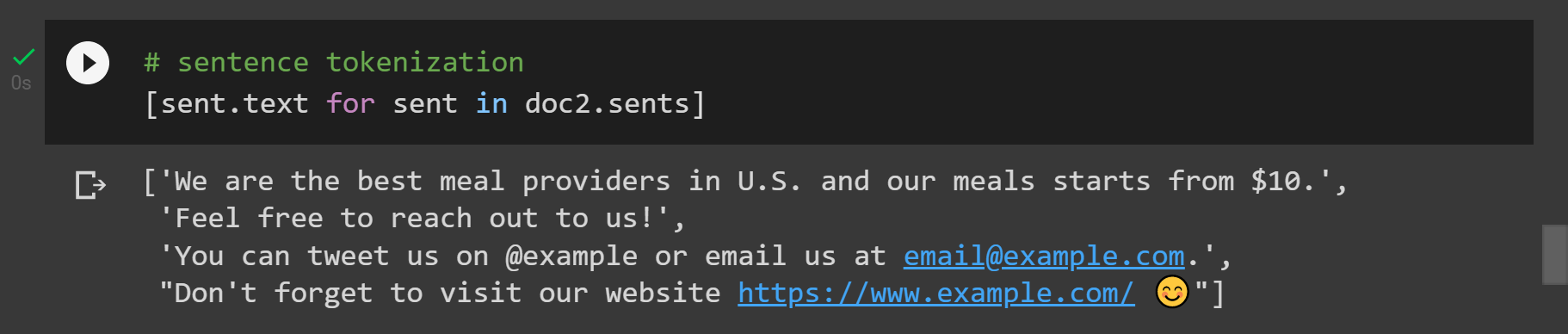
🔍 Наблюдения:
- Мы видим, что spaCy с такой легкостью обрабатывает как простые, так и сложные текстовые последовательности.
Краткое содержание
Всего одной строкой кода spaCy позволяет нам создавать точные токены.
Вот почему spaCy стала моей предпочтительной библиотекой НЛП для предварительной обработки текста по сравнению с другими.
🏆
Визуализация токенов и сущностей
spaCy также позволяет нам визуализировать токены и объекты в корпусе для лучшего исследования данных. Он предлагает нам встроенный визуализатор под названием displacy.
Это помогает нам визуализировать токены в объекте doc и их связь друг с другом.
Что такое сущности? 🤔
Сущности — это наиболее важные фрагменты определенного предложения, такие как словосочетания с существительными, глагольные фразы или и то, и другое.
Мы подробно рассмотрим сущности в будущем обсуждении.
Как токенизация происходит под капотом в spaCy
Вот как интеллектуальная система spaCy создает точные токены.
См. диаграмму ниже.
- Во-первых, он разбивает все слова на пробелы.
- Затем он отделяет префиксы от этих слов.
- Затем повторяется то же самое с исключениями и суффиксами.
- В конце концов, вы получаете правильные токены.

Поэтому spaCy обрабатывает все токены, включая префиксы, суффиксы, инфиксы и исключения.
В заключение
Сегодня мы обсудили, что такое токенизация, почему это важно и как это сделать.
Мы также увидели, как токенизировать данный корпус с помощью различных методов, и заметили, что spaCy намного превосходит остальные доступные методы.
Надеюсь, вам понравилось! Не стесняйтесь оставлять свои отзывы и вопросы в комментариях ниже. Вы также можете связаться со мной по:






