
BERT (двунаправленное представление для трансформаторов) был впервые предложен Google в 2018 году. В 2019 году Google объявил, что начал использовать BERT в своей поисковой системе, а к концу 2020 года он использовал BERT почти в каждом англоязычном запросе. Хотя основной целью этого было улучшение понимания значения запросов, связанных с поиском Google, BERT становится одной из наиболее важных и полных архитектур для различных задач на естественном языке, генерируя самые современные результаты по классификации пар предложений. задание, вопросно-ответное задание и др.
В этом блоге я покажу вам, как я настроил BERT для классификации твитов независимо от того, сообщают ли они что-то, связанное с бедствием, или нет. Недавно я принял участие в конкурсе kaggle, в котором моя модель набрала 0,83665 балла F1 и заняла 101 место из 1300 команд. Мы пройдемся по коду, и в конце все ресурсы будут связаны. Но прежде чем перейти к коду, мы кратко разберемся, как работает BERT.
Этот блог в основном состоит из двух частей:
- Обзор того, как работает BERT.
- Понимание кода для тонкой настройки BERT для конкретного варианта использования.
Понимание архитектуры BERT
До того, как был предложен BERT, языковая модель использовала заданный текст слева направо, а затем комбинировала его с написанием справа налево. Этот однонаправленный подход хорошо работает для создания предложений. Например: генерация пропущенных слов и подобные задачи.
Теперь BERT представляет собой языковую модель с двунаправленным обучением, что в основном означает, что мы можем лучше понимать текстовые последовательности по сравнению с однонаправленным обучением.
BERT обучается с помощью специальной техники под названием Masked LM (MLM), которая случайным образом маскирует слова в предложении, а затем пытается их предсказать. Используя этот поток, модель сможет использовать контекст перед замаскированным словом и контекст после него, чтобы предсказать слово. Следовательно, он получает полный контекст предложения.
Обучение BERT состоит из двух этапов.
- Обучение с полуучителем на большом количестве текстов.
- Обучение под наблюдением по конкретной задаче с набором данных меток.
Этап частично контролируемого обучения:
Модель обучается определенной задаче, которая позволяет ей распознавать закономерности в языковой последовательности. Он обучается на больших корпусах, взятых из общедоступных книг, и огромном количестве текстовых данных, вычищенных из Википедии. В конце процесса обучения у модели развились способности обработки языка, которые помогают выполнять контролируемые учебные задачи.

Этап обучения под наблюдением:
На этапе контролируемого обучения выходные данные предыдущего шага передаются в классификатор для прогнозирования данной задачи, которая в нашем случае будет заключаться в том, чтобы предсказать, сообщает ли данный текст (твит) что-то, связанное с бедствием, или нет. Этот классификатор может быть моделью машинного обучения или глубокого обучения. Мы использовали двухслойную плотную нейронную сеть для задачи классификации.

В настоящее время доступны два типа модели BERT:
- База BERT: 12 уровней, 768 скрытых узлов, 12 заголовков, 110 млн параметров.
- BERT-большой: 24 уровня, 1024 скрытых узла, 16 заголовков, 340M параметров.
Слои в вышеуказанном состоянии относятся к трансформерам. BERT — это, по сути, несколько энкодеров, сложенных вместе. Если вы мало знакомы с трансформерами, то перейдите по этой ссылке.
Входные данные
Первый токен входной последовательности — это токен [CLS], обозначающий задачу классификации. BERT принимает на вход последовательность слов. Каждый слой кодировщика обращает внимание на последовательность и передает ее в нейронную сеть с прямой связью, а вывод передает следующему кодировщику. Это происходит 12 раз в BERT-base и 24 раза в BERT-large.
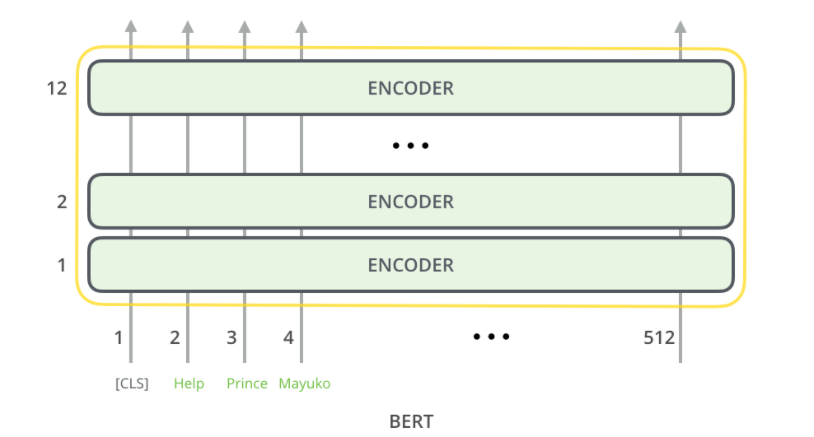
Вывод
Все токены выводят соответствующий вектор, и для классификации мы рассматриваем только первый вектор, которому мы передаем токен [CLS]. Затем этот вектор используется в качестве входных данных классификатора, такого как однослойная нейронная сеть.

Прыжок в код
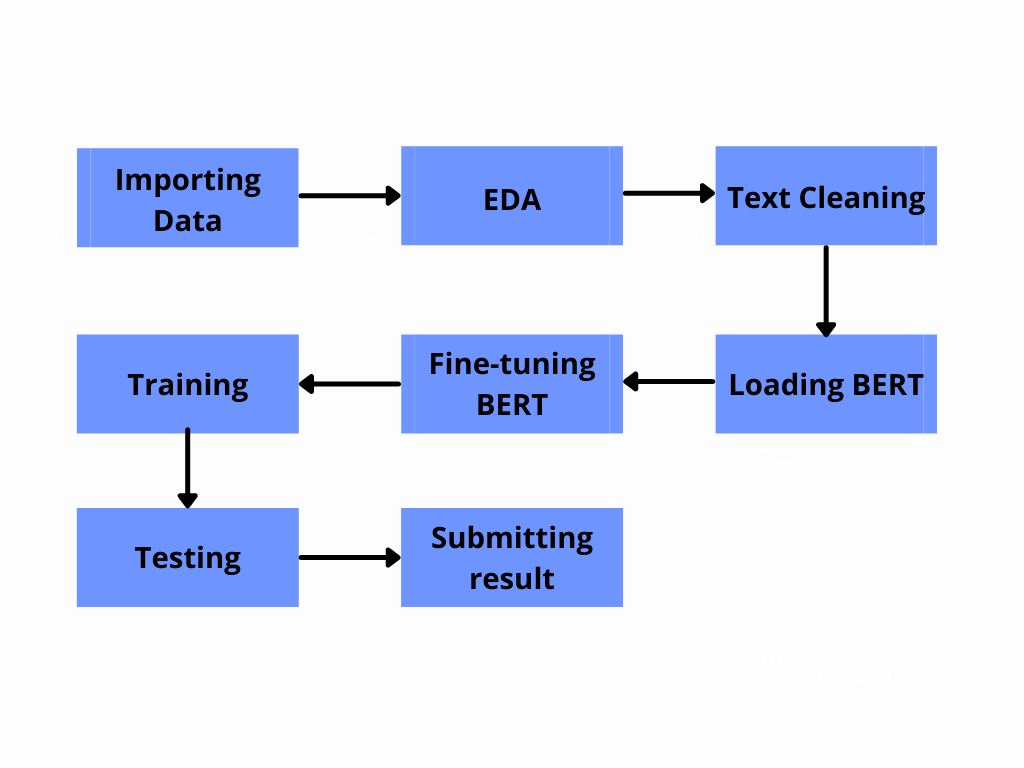
В этом разделе мы рассмотрим код и поймем, как именно можно настроить BERT для конкретного случая использования. Наряду с этим мы рассмотрим несколько примеров EDA в текстах и очистку текста. Краткий обзор этапов проекта можно увидеть здесь.
Мы будем использовать библиотеку huggingface для загрузки модели BERT. Huggingface — одна из наиболее часто используемых библиотек в области НЛП в наши дни. У них есть простые API, которые делают создание моделей чрезвычайно нетребовательным. В частности, в нашем коде мы будем использовать модель bert-large-uncased. Подробнее можно посмотреть здесь.
Импорт библиотек
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import re
import warnings
warnings.filterwarnings('ignore')
from transformers import AutoTokenizer, TFBertModel
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import BinaryCrossentropy
from tensorflow.keras.metrics import BinaryAccuracy
from tensorflow.keras.utils import plot_model
#tf.config.experimental.list_physical_devices('GPU')
Это необходимые библиотеки, которые мы собираемся использовать. Я выбрал Tensorflow/Keras для построения этой модели. Ниже я объясню, что именно делает каждый импорт:
- numpy — Для научных расчетов.
- pandas — для обработки набора данных.
- matplotlib и seaborn — чтобы построить наши данные.
- re — Re — это библиотека регулярных выражений в Python.
- предупреждения — эта библиотека используется для фильтрации различных предупреждений, которые генерируются при выполнении определенного фрагмента кода. В следующей строке вы можете видеть, что мы передаем аргументы «игнорировать», которые в основном игнорируют любое предупреждение, генерируемое системой.
- трансформеры — это библиотека трансформеров от Huggingface. Он предустановлен в ноутбуках Kaggle. Импортируем из него автотокенизатор и модель TFbert. Я объясню, что они делают при их использовании позже в коде.
- Input, Dense — эти слои присутствуют в keras.layers. Мы будем использовать это для построения классификатора DL и для ввода BERT.
- Адам — мы будем использовать оптимизатор Adam, присутствующий в keras.optimizers.
- BinaryCrossentropy — мы будем использовать Binary Cross Entropy для расчета потерь нашей модели.
- BinaryAccuracy — мы будем использовать это для расчета точности нашей модели.
- plot_model — Это поможет нам предоставить нам визуальное представление нашей модели.
Загрузка данных
train = pd.read_csv('../input/nlp-getting-started/train.csv', usecols=['id','text','target'])
test = pd.read_csv('../input/nlp-getting-started/test.csv', usecols=['id','text'])
sample = pd.read_csv('../input/nlp-getting-started/sample_submission.csv')
Функция read_csv от pandas поможет нам загрузить наш набор данных в фрейм данных. Позже мы будем использовать этот набор данных для построения различных атрибутов наших данных. Нас интересуют только идентификатор, текст и цель (только для набора поездов), поэтому мы используем usecols для указания интересующих нас столбцов.
Теперь давайте посмотрим на наши данные. Мы используем функцию .head(), чтобы получить представление о данных.

Итак, наша проблема — проблема бинарной классификации. Целевой столбец переключается между 1 и 0 в зависимости от текстового столбца. Если твит касается стихийного бедствия, то целевой столбец равен 1, а в противном случае — 0. Мы также обнаруживаем, что обучающая выборка содержит в общей сложности 7613 примеров. Мы используем функцию .shape, чтобы узнать его форму.
Исследовательский анализ данных
Давайте проверим, не являются ли наши данные несбалансированными. Мы используем гистограмму, чтобы проверить это. Функция value_counts() подсчитывает, сколько раз значение встречается в данном наборе.
x = train.target.value_counts()
sns.barplot(x.index, x)
plt.gca().set_ylabel('samples')

Похоже, что наши данные не сильно несбалансированы, поэтому мы не будем применять какие-либо причудливые методы, чтобы помочь с дисбалансом.
Затем мы берем все примеры в нашем обучающем наборе, чье значение target равно 1, преобразуем его в строку, а затем применяем функцию Python len(). чтобы получить длину каждого символа в одном примере. Затем мы делаем то же самое со значением target 0. Мы сохраняем выходные данные и рисуем их.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12,6))
train_len1 = train[train['target'] == 1]['text'].str.len()
ax1.hist(train_len1, color='red')
ax1.set_title("Disaster Tweet")
train_len2 = train[train['target'] == 0]['text'].str.len()
ax2.hist(train_len2, color='green')
ax2.set_title("Non disaster Tweet")
fig.suptitle("Characters in tweet")
plt.show()
print(train_len1.shape, train_len2.shape)

Следующая ячейка кода очень похожа на предыдущую, за исключением того, что мы разбиваем текст с помощью функции split(), а затем используем лямбда для получить длину входной строки. Мы применяем лямбда-функцию, используя функцию map, встроенную в python.

Затем мы проверяем, сколько слов в среднем приходится на входной текст. График ниже показывает нам это. Мы разделяем строку, которая возвращает список всех слов в нашем тексте, затем мы берем ее длину и применяем функцию среднего, которая поможет нам получить среднее количество слов в тексте. Красная и зеленая линии на графике показаны потому, что мы установили kde=True в нашем коде. KDE означает оценку плотности ядра. Подробнее об этом можно прочитать здесь.

Очистка текста
Очистка текста — очень важный шаг в любой проблеме НЛП. Я использовал процесс очистки текста из другой записной книжки, которую нашел в kaggle. Я выбрал процесс очистки текста этой записной книжки, потому что автор просмотрел каждую аббревиатуру и превратил ее в полную форму. Я не буду вставлять сюда всю ячейку кода, потому что она слишком длинная. Но, пожалуйста, проверьте точный код ячейки здесь.
def clean(tweet):
# These will change special characters
tweet = re.sub(r"\x89Û_", "", tweet)
tweet = re.sub(r"\x89ÛÒ", "", tweet)
tweet = re.sub(r"\x89ÛÓ", "", tweet)
tweet = re.sub(r"\x89ÛÏWhen", "When", tweet)
tweet = re.sub(r"\x89ÛÏ", "", tweet)
tweet = re.sub(r"China\x89Ûªs", "China's", tweet)
tweet = re.sub(r"let\x89Ûªs", "let's", tweet)
tweet = re.sub(r"\x89Û÷", "", tweet)
tweet = re.sub(r"\x89Ûª", "", tweet)
tweet = re.sub(r"\x89Û\x9d", "", tweet)
tweet = re.sub(r"å_", "", tweet)
tweet = re.sub(r"\x89Û¢", "", tweet)
tweet = re.sub(r"\x89Û¢åÊ", "", tweet)
tweet = re.sub(r"fromåÊwounds", "from wounds", tweet)
....
tweet = re.sub(r"SHGames", "Sledgehammer Games", tweet)
tweet = re.sub(r"bedhair", "bed hair", tweet)
tweet = re.sub(r"JoelHeyman", "Joel Heyman", tweet)
tweet = re.sub(r"viaYouTube", "via YouTube", tweet)
# links and urls
tweet = re.sub(r"https?:\/\/t.co\/[A-Za-z0-9]+", "", tweet)
# punctuation
punctuations = '@#!?+&*[]-%.:/();$=><|{}^' + "'`"
for p in punctuations:
tweet = tweet.replace(p, f' {p} ')
# Acronyms
tweet = re.sub(r"MH370", "Malaysia Airlines Flight 370", tweet)
tweet = re.sub(r"m̼sica", "music", tweet)
tweet = re.sub(r"okwx", "Oklahoma City Weather", tweet)
....
tweet = re.sub(r"Suruc", "Sanliurfa", tweet)
# Grouping same words without embeddings
tweet = re.sub(r"Bestnaijamade", "bestnaijamade", tweet)
tweet = re.sub(r"SOUDELOR", "Soudelor", tweet)
return tweet
train['text'] = train['text'].apply(lambda s : clean(s))
Приведенная выше функция вернет нам очищенный набор данных. Мы используем регулярные выражения для очистки данных. re.sub находит и заменяет все вхождения первого аргумента вторым аргументом. Если вы не очень хорошо знакомы с регулярными выражениями, то обязательно посмотрите этот замечательный учебник.
Также было видно, что в наших данных было много URL-адресов. Поэтому мы удалили их также с помощью RE. Для знаков препинания мы не использовали re. Мы сохранили все возможные знаки препинания в строке, прошлись по ней и проверили, присутствует ли какой-либо из элементов строки в текстовом вводе.
Загрузка модели BERT
Мы уже импортировали модель BERT и соответствующий токенизатор при импорте необходимых библиотек.
Модели Берта можно найти здесь: https://huggingface.co/models. Здесь мы используем модель bert-large-uncased. Но больше моделей можно найти по ссылке выше.
«bert-large-uncased» — это точная модель bert, которую мы собираемся использовать. Мы используем AutoTokenizer, и он создаст универсальный класс токенизатора, который будет создан как один из классов токенизатора библиотеки обнимающих лиц при создании с помощью метода класса AutoTokenizer.from_pretrained(). Мы можем передать через него модель BERT по нашему выбору, чтобы получить соответствующие токенизаторы.
tokenizer = AutoTokenizer.from_pretrained('bert-large-uncased')
bert = TFBertModel.from_pretrained('bert-large-uncased')
Давайте передадим строку и посмотрим, как наш токенизатор ее изменит.
tokenizer('Shine on you crazy diamond.')

Итак, как вы можете видеть здесь, он возвращает «input_ids», «token_type_ids» и «attention_mask». В этом случае мы будем использовать «input_ids» и «attention_masks». Мы передадим их обоих в модель. Если вам интересно, почему input_ids имеет 7 чисел, даже если во вводе было 5 слов, то это потому, что первое число (101) и последнее (102) являются токенами по умолчанию. Первый токен — это [CLS], который мы обсуждали выше, а последнее число — это специальный токен, который указывает на конец предложения.
Теперь давайте преобразуем входные необработанные тексты в формат ввода BERT. Мы делаем это с помощью токенизатора, который мы создали выше. В следующем фрагменте кода мы преобразуем входной набор данных в форму токенизатора, для add_special_tokens установлено значение true, потому что мы хотим заменить неизвестные слова специальными токенами, мы устанавливаем максимальную длину 73 и используем усечение и заполнение. Нам не нужны идентификаторы типов токенов, но нам нужна маска внимания, чтобы получить вывод в виде входных данных BERT. Этот токенизатор будет выводить input_ids и внимание_маски, которые мы будем использовать в модели BERT в качестве входных данных. input_id — это просто идентификаторы числовых представлений текстов. Attention_mask полезен, когда мы добавляем отступы к токенам ввода. Маска внимания сообщает нам, какие input_id соответствуют заполнению. Заполнение добавлено, потому что мы хотим, чтобы все входные предложения были одинаковой длины (по крайней мере, для пакета), чтобы мы могли правильно формировать тензорные объекты.
x_train = tokenizer(
text=train.text.tolist(),
add_special_tokens=True,
max_length=73,
truncation=True,
padding=True,
return_tensors='tf',
return_token_type_ids = False,
return_attention_mask = True,
verbose = True)
Вот как мы создаем файл x_train. Теперь создать y_train очень легко, нам просто нужно сохранить целевой столбец в списке и назвать переменную y_train.
y_train = train.target.values
Построение модели
В следующем фрагменте кода мы устанавливаем два входных слоя для модели: один для входных идентификаторов, а другой — для маски внимания. Передаем их модели bert. Модель bert обеспечивает два выхода. sequence_output и pooled_output, мы будем использовать объединенные выходные данные, поскольку они представляют фактические функции модели. Итак, это второй выход, поэтому мы используем [1]. Затем мы используем очень простую ИНС с двумя слоями со 120 нейронами и 32 нейронами соответственно. Мы используем функцию активации relu на выходе с некоторыми исключениями. Наконец, мы используем один нейрон в выводе, поскольку это проблема бинарной классификации для предсказания того, является ли данный твит катастрофическим или нет. (0 или 1) Мы используем «сигмоидальную» функцию активации для этой задачи бинарной классификации. Мы установили второй уровень как обучаемый, потому что мы хотим, чтобы модель BERT была обучаемой.
max_len = 73
input_ids = Input(shape=(max_len,), dtype=tf.int32, name="input_ids")
input_mask = Input(shape=(max_len,), dtype=tf.int32, name="attention_mask")
embeddings = bert(input_ids,attention_mask = input_mask)[1]
out = tf.keras.layers.Dropout(0.1)(embeddings)
out = Dense(128, activation='relu')(out)
out = tf.keras.layers.Dropout(0.1)(out)
out = Dense(32,activation = 'relu')(out)
y = Dense(1,activation = 'sigmoid')(out)
model = tf.keras.Model(inputs=[input_ids, input_mask], outputs=y)
model.layers[2].trainable = True
Фаза обучения
Мы используем оптимизатор Adam для отслеживания наших потерь. Затем мы используем BinaryCrossentropy для расчета наших потерь. И используйте метрику точность, а затем мы, наконец, скомпилируем нашу модель.
Если вы не знаете, как работает оптимизатор Adam или потеря BinaryCrossEntropy, обратитесь к этим удивительным ресурсам.
Адам
- Блог: https://machinelearningmastery.com/adam-optimization-algorithm-for-deep-learning/
- Видео: https://www.youtube.com/watch?v=JXQT_vxqwIs&ab_channel=DeepLearningAI
Бинарнаякроссэнтропия
- Блог: https://www.bing.com/search?q=BinaryCrossEntropy&cvid=986370ad4e7e4caa92d9aba3a0958783&aqs=edge.0.69i59l2j0l7.1874j0j4&FORM=ANAB01&PC=ACTS
- Видео : https://www.youtube.com/watch?v=Md4b67HvmRo&ab_channel=DigitalSreeni
optimizer = Adam(
learning_rate=6e-06, # this learning rate is taken from huggingface website
epsilon=1e-08,
decay=0.01,
clipnorm=1.0)
# Set loss and metrics
loss = BinaryCrossentropy(from_logits = True)
metric = BinaryAccuracy('accuracy'),
# Compile the model
model.compile(
optimizer = optimizer,
loss = loss,
metrics = metric)
Затем мы строим нашу модель, используя plot_model, которую мы импортировали выше. Это дает нам визуальное представление нашей модели.
plot_model(model, show_shapes = True)

Теперь пришло время обучить нашу модель. Мы передаем два входа как ключ-значение. Мы устанавливаем размер партии равным 32 и обучаем модель на 12 эпох. Здесь мы не выполняем разделение проверки, так как у нас нет огромного набора данных, поэтому было бы лучше использовать все обучающие данные для обучения модели, а не разделять ее. Мы будем использовать тестовый набор данных для проверки наших результатов для данного набора задач.
train_history = model.fit(
x ={'input_ids':x_train['input_ids'],'attention_mask':x_train['attention_mask']} ,
y = y_train, epochs=12, batch_size=32
)
После обучения в течение 12 эпох мы получаем около 87% бинарной точности.

Этап тестирования
Теперь мы преобразуем тексты тестовых файлов в форму ввода BERT, чтобы наша модель могла предсказать, связаны ли тексты с какой-либо катастрофой или нет. Мы используем ту же процедуру, что и при преобразовании обучающей выборки.
x_test = tokenizer(
text=test.text.tolist(),
add_special_tokens=True,
max_length=73,
truncation=True,
padding=True,
return_tensors='tf',
return_token_type_ids = False,
return_attention_mask = True,
verbose = True)
Теперь мы будем использовать модель для прогнозирования x_test и сохранения его в списке. Подобно нашему x_train, наш x_test также предоставляет несколько выходных данных, из которых мы будем использовать только «input_ids» и «attention_mask».
Если значение в predicted (который представляет собой список вероятностей Python для каждого текстового примера) больше 0,5, тогда np.where изменяет его на 1, или, если меньше 0,5, оно меняет его на 0 , И мы также меняем его форму на 3263, потому что Kaggle ожидает, что отправленный результат будет в этой форме.
predicted = model.predict({'input_ids':x_test['input_ids'],'attention_mask':x_test['attention_mask']})
y_predicted = np.where(predicted>0.5,1,0)
y_predictedd = y_predicted.reshape((1,3263))[0]
Наконец, мы сохраняем вывод в файле csv, который мы будем загружать в соревновании Kaggle. Образец CSV-файла уже предоставлен и имеет правильный формат. Поэтому мы меняем столбец «id» на id наших тестовых данных и меняем столбец «target» на наш список y_predicted. Затем мы используем метод to_csv, предоставленный pandas, чтобы преобразовать его в файл csv.
sample['id'] = test.id
sample['target'] = y_predictedd
sample.to_csv('submission_a.csv',index = False
Заключение
В этом руководстве я объяснил, как точно настроил модель BERT для классификации твитов о стихийных бедствиях. Я занял 101-е место из 1300 команд, что составляет почти 7% лучших. Мы прошлись по каждой строке кода, как я уже упоминал, и надеюсь, что смог правильно объяснить каждую строку кода, как и обещал в начале. Если нет, не стесняйтесь каждый меня. Пожалуйста, проголосуйте за блокнот, если вам нравится моя работа. Удачного кодирования!
Электронная почта: [email protected]
Мой LinkedIn: https://www.linkedin.com/in/aunkit-chaki-38807b174/
Полный код: Классификация твитов с использованием BERT (объяснение) | Kaggle
Ресурсы
- Записная книжка по очистке данных: НЛП с твитами-катастрофами — EDA, очистка и BERT | Kaggle
- Иллюстрированный BERT, ELMo и компания. (Как НЛП взломало трансферное обучение) — Джей Аламмар — Визуализация машинного обучения по одной концепции за раз. (jalammar.github.io)
- Hugging Face — сообщество ИИ, строящее будущее.






