В этой истории я хотел бы исследовать, вероятно, один из важных алгоритмов обучения без учителя, а именно анализ основных компонентов (АПК).
Алгоритм АПК довольно технический, но я попытался объяснить его в упрощенной форме.
Далее я представлю теорию этого метода, математическую интуицию, а также основные преимущества и недостатки этого метода.
Прежде чем перейти к PCA, я хочу пролить свет на Уменьшение размерности.
Давайте разберемся, что это на самом деле означает.
Уменьшение размерности: это просто относится к уменьшение количества входных переменных или признаков в наборе обучающих данных. Наличие большого количества переменных может привести к переоснащению модели, и мы также можем столкнуться с проблемами при изучении взаимосвязи между переменными.
Итак, наша главная проблема заключается в том, как выбрать переменные из всего множества входных переменных. С технической точки зрения, как мы можем уменьшить размер нашего пространства признаков. Этот частный случай известен как уменьшение размерности.
Существуют различные методы уменьшения размерности. Однако для простоты я сосредоточусь на двух самых популярных методах:
1) Выбор признаков:При выборе признаков используются статистические или оценочные методы, чтобы выбрать, какие признаки оставить, а какие оставить. быть удалены.
Выбор функций также известен как исключение функций, потому что мы склонны сокращать пространство функций, исключая функции. Мы пытаемся удалить или отфильтровать избыточные или нежелательные функции из нашего набора данных.
2) Извлечение функций: Извлечение функций предназначено для создания нового, меньшего набора функций, который по-прежнему захватывает большую часть полезного. Информация.
Существует множество алгоритмов, в которые встроены средства выбора и извлечения признаков.
Анализ основных компонентов – это метод выделения признаков.
Теперь, когда у нас есть представление о том, что такое уменьшение размерности, давайте углубимся и разберемся с PCA.
Итак, как упоминалось выше, PCA — это алгоритм уменьшения размерности, что означает, что он уменьшает размерность больших наборов данных путем преобразования большого количества входных переменных в меньшую, которая по-прежнему будет содержать большую часть информации в большем количестве входных переменных. .
PCA также используется в качестве инструмента для визуализации, фильтрации шумов, извлечения признаков и проектирования и многого другого.
Основная идея PCA довольно ясна; Это уменьшает количество входных переменных в наборе данных, сохраняя при этом как можно больше информации.
Вот почему PCA считается методом извлечения признаков!
Это все о теории PCA. Далее мы поймем, как работает PCA.
Я объясню математическую интуицию, лежащую в основе PCA, на следующем примере. Я использовал двумерные данные, потому что их легче визуализировать.

На изображении выше данные двух переменных представлены на точечной диаграмме.
Шаг 1. Найдите центр данных. Для этой цели возьмем среднее значение всех наблюдений по двум переменным осям.
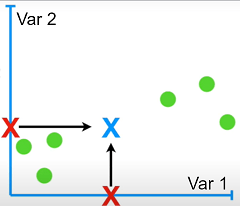
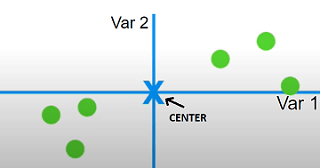
Шаг 2: Как только центр будет получен, мы переместим наблюдение таким образом, чтобы центр совпал с началом плоскости.
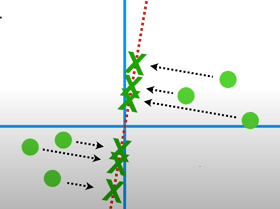
Шаг 3: Мы должны найти первый основной компонент (PC1). Мы должны найти линию наилучшего соответствия для точек данных, которые будут проходить через центр. Мы можем выбрать любую случайную линию, и точки данных проецируются на эту линию.
Шаг 4: Теперь нам нужно найти расстояния между спроецированными точками до начала координат, возвести их в квадрат и максимизировать их сумму, как показано ниже.
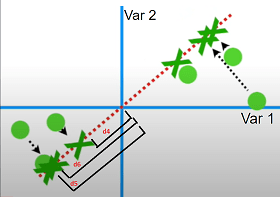
Таким образом, для алгоритма PCA линия наилучшего соответствия — это линия, при которой сумма всех расстояний от проецируемых точек до начала координат максимальна.
Шаг 5: Теперь нам нужно знать наклон линии. Предположим, что наш наклон равен 0,25, что означает, что линия наилучшего соответствия состоит из четырех частей переменной 1 и одной части переменной 2.
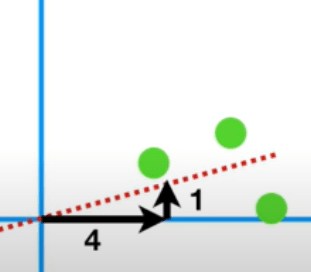
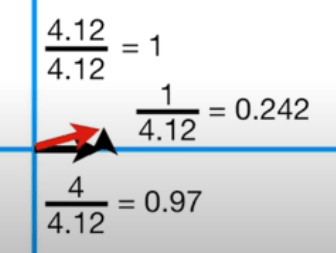
Здесь B = 4 и C = 1. Теперь с помощью теоремы Пифагора мы можем легко найти значение A.
PCA масштабирует это значение так, что A становится вектором единичной длины, что делает A = 1, это единичный вектор A является собственным вектором!
Сумма квадратов расстояний проецируемых точек данных до начала координат (т. е. d1, d2, d3, d4..) является собственными значениями!
Итак, из приведенного выше небольшого примера мы можем понять, что для PC1, переменная 1 почти в четыре раза важнее, чем переменная 2.
Шаг 6: Мы почти на полпути к нашей цели, но есть еще одна последняя остановка, то есть найти второй главный компонент (PC2). Два компонента, потому что мы используем только две переменные.
Так как есть 0 корреляция между основными компонентами. Наш PC2 будет просто вектором, ортогональным к PC1, который мы только что обнаружили.
PC2 будет просто линией, проходящей через начало координат, ортогональным к PC1. Таким образом, PC2 будет рассчитываться как 1 часть переменной 1, которая должна быть смешана с 4 частями переменной 2.
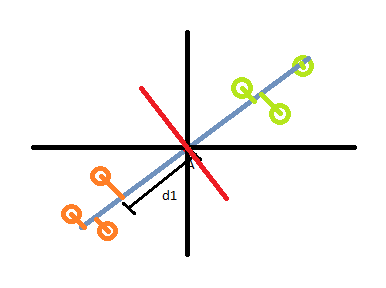
Красная линия — это ПК2.
Теперь эти 2 компонента бесполезны без объясненной дисперсии.
Что такое объясненная дисперсия?
Объясненная дисперсия показывает, насколько вариативность данных объясняется каждым основным компонентом.
Мы можем получить соответствующую дисперсию PC, суммируя квадраты расстояний для обоих основных компонентов и разделив эти значения на размер выборки данных.
Основные компоненты ранжируются в порядке их объясненной дисперсии. Мы выбираем верхние основные компоненты, если общая объясненная дисперсия достигает достаточного значения.
Плюсы и минусы:
Плюсы:
1) Уменьшение переобучения:PCA помогает модели не переобучать, удаляя нежелательные функции из набора данных.
2) Помогает в визуализации: трудно визуализировать данные с большим размером (4D или более), PCA помогает визуализировать их, уменьшая размерность.
3) Улучшает производительность модели: слишком много функций приведет к тому, что модель не будет давать наилучшие и точные результаты, но благодаря PCA она ускоряет алгоритм машинного обучения, избавляясь от коррелированных переменных.
Минусы:
1) Стандартизация является обязательной для набора данных перед внедрением PCA, иначе PCA не сможет оптимизировать основные компоненты.
2) Вероятность потери информации, если мы этого не сделаем. Тщательно выбирать главные компоненты.
3) Входные переменные становятся менее интерпретируемыми.
Так это конец! Надеюсь, мне удалось донести до своих читателей основную суть этого прекрасного алгоритма.
Я добавляю несколько важных ресурсов, которые оказались полезными при изучении этого алгоритма:
https://www.youtube.com/watch?v=FgakZw6K1QQ
https:/ /www.youtube.com/watch?v=OFyyWcw2cyM
https://arxiv.org/pdf/1404.1100.pdf
Всем приятного обучения.. :)






