Настройка визуализатора сущностей displaCy
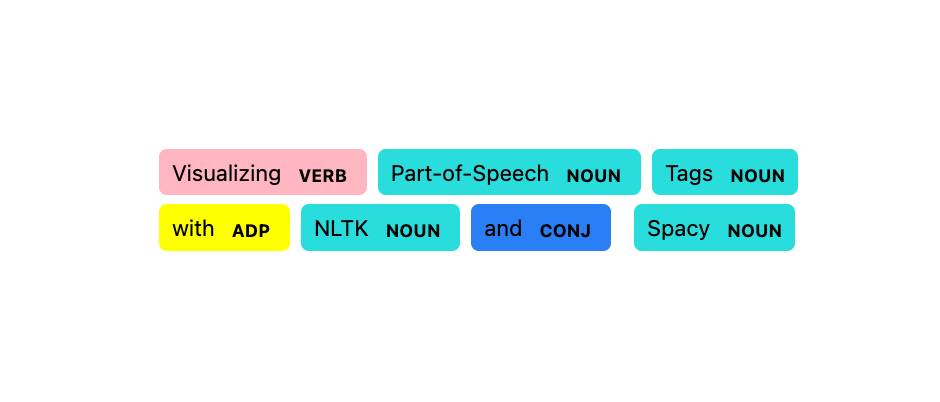
В этом уроке мы разработаем функцию для визуализации тегов части речи (POS) с помощью NLTK и SpaCy.
Полученная функция превратит это

в это:

Мотивация
Теги POS – это метод, используемый при обработке естественного языка. Он классифицирует токены в тексте как существительные, глаголы, прилагательные и так далее. В Python для этой цели можно использовать библиотеку NLTK.
import nltk from nltk import word_tokenize text = "This is one simple example." tokens = word_tokenize(text) tags = nltk.pos_tag(tokens, tagset = "universal")
В приведенном выше фрагменте кода пример text = "This is one simple example." сначала токенизируется (This, is, one, simple, example и .) с помощью функции word_tokenize(). Затем жетоны помечаются POS-тегами с помощью функции pos_tag(). В этом примере мы будем использовать tagset = "universal", потому что он использует более общий набор тегов, в отличие от набора тегов по умолчанию, который предоставляет более подробные теги.
Ниже вы можете увидеть токены с POS-тегами примера предложения.

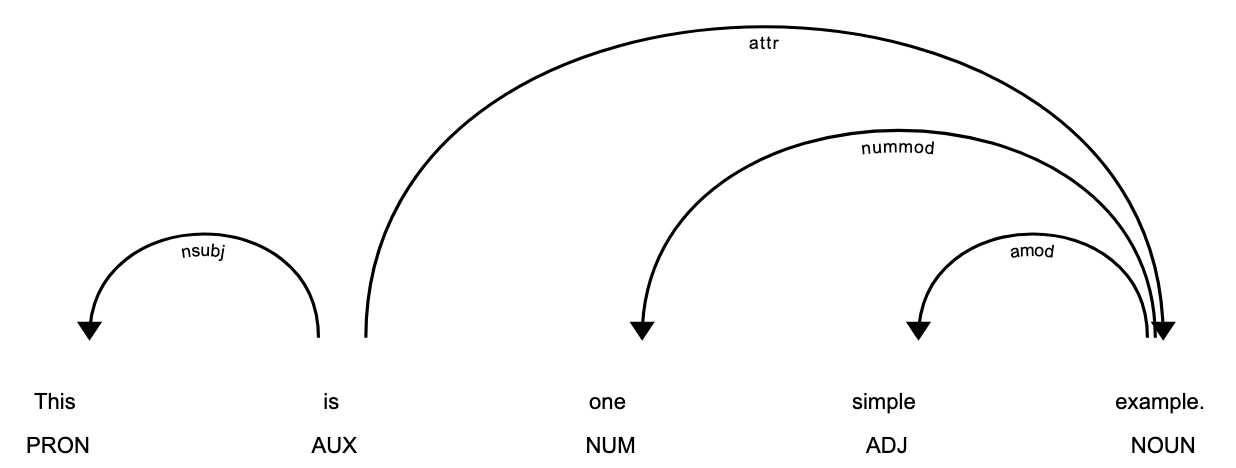
SpaCy поставляется с визуализатором под названием displaCy. Например, вы можете отображать теги POS и синтаксические зависимости следующим образом с помощью style = "dep".
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
displacy.render(doc, style = "dep")
Более красочный вариант — выделить именованные объекты и их метки с помощью style = "ent".
displacy.render(doc, style = "ent")

К сожалению, опция style = "dep" не использует цвет для визуализации POS-тегов, а style = "ent" не отображает POS-теги. Поэтому разработаем функцию подсветки POS-тегов по аналогии с подсветкой сущностей SpaCy с помощью NLTK.
Разработка функции визуализации
В этом разделе мы разработаем функцию визуализации в два простых шага:
- Настройка параметров отображения
- Заполнение словаря сущностей
Настройка параметров отображения
Хотя подсветка именованных объектов displaCy не выделяет теги POS из коробки, вы можете настроить то, что она должна подсвечивать.
Вы также можете использовать displaCy для ручного рендеринга данных. […] Если вы установите
manual=Trueнаrender()илиserve(), вы сможете передавать данные в формате displaCy в виде словаря (вместо объектовDoc). — [2]
from spacy import displacy
displacy.render(doc,
style = "ent",
options = options,
manual = True)
Визуализатор сущностей позволяет настраивать следующие
options:entsтипы сущностей для выделения.colorsПереопределение цвета. Типы сущностей должны быть сопоставлены с именами или значениями цветов. — [2]
В этом примере типы сущностей для выделения будут разными тегами POS. Мы будем использовать tagset = "universal". Этот набор тегов состоит из следующих 12 тегов грубой обработки: [1]
VERB — глаголы (все времена и наклонения)
NOUN — существительные (нарицательные и собственные)
PRON — местоимения
ADJ — прилагательные
ADV — наречия
ADP — прилагательные ( предлоги и послелоги)
CONJ — союзы
DET — определители
NUM — количественные числительные
PRT — частицы или другие служебные слова
X — прочее: иностранные слова, опечатки, сокращения
. - пунктуация
Мы будем использовать все теги POS, за исключением «X» и «.», чтобы ents и colors option выглядели так.
pos_tags = ["PRON", "VERB", "NOUN", "ADJ", "ADP", "ADV", "CONJ", "DET", "NUM", "PRT"]
colors = {"PRON": "blueviolet",
"VERB": "lightpink",
"NOUN": "turquoise",
"ADJ" : "lime",
"ADP" : "khaki",
"ADV" : "orange",
"CONJ" : "cornflowerblue",
"DET" : "forestgreen",
"NUM" : "salmon",
"PRT" : "yellow"}
options = {"ents": pos_tags, "colors": colors}
В этом разделе вы можете решить, какие теги вы хотите использовать, и настроить цвета.
Заполнение словаря сущностей
Далее нам нужно определить файл doc.
doc = {"text" : text, "ents" : ents}
В то время как "text" — это просто текст, который мы хотим визуализировать, "ents" — это словарь каждой сущности, которую нужно выделить.
Для каждой сущности нам нужно определить индексы start и end в тексте. Кроме того, нам нужно определить label объекта, который в нашем случае является тегом POS.
Начнем с токенизации текста и POS-маркировки токенов. В отличие от фрагмента кода в разделе «Мотивация», мы будем использовать функцию TreebankWordTokenizer вместо функции word_tokenize(). Причина этого в том, что TreebankWordTokenizer предлагает больше гибкости, которая нам понадобится через минуту.
import nltk from nltk.tokenize import TreebankWordTokenizer as twt # Tokenize text and pos tag each token tokens = twt().tokenize(text) tags = nltk.pos_tag(tokens, tagset = "universal")
Токены POS с тегом tags выглядят следующим образом:
[('This', 'DET'),
('is', 'VERB'),
('one', 'NUM'),
('simple', 'ADJ'),
('example', 'NOUN'),
('.', '.')]
Как упоминалось выше, TreebankWordTokenizer предлагает функцию для получения диапазонов для каждого токена, что нам нужно для словаря "ents".
# Get start and end index (span) for each token span_generator = twt().span_tokenize(text) spans = [span for span in span_generator]
spans выглядит так:
# text = "This is one simple example." [(0, 4), (5, 7), (8, 11), (12, 18), (19, 26), (26, 27)]
Теперь, когда у нас есть tags и spans, мы можем заполнить словарь "ents".
# Create dictionary with start index, end index, pos_tag for each token
ents = []
for tag, span in zip(tags, spans):
if tag[1] in pos_tags:
ents.append({"start" : span[0],
"end" : span[1],
"label" : tag[1] })
Вот и все!
Результаты и заключение
В этом уроке мы разработали короткую функцию для визуализации тегов POS с NLTK и SpaCy.
Полная функция показана ниже:
Давайте нарисуем несколько примеров:
visualize_pos("Call me Ishmael.")

visualize_pos("It was a bright cold day in April, and the clocks were striking thirteen.")

visualize_pos("The train leaves here at 9AM.")

Понравилась эта история?
Если вы хотите получать мои новые истории прямо на свой почтовый ящик, не забудьте подписаться!
Стань участником Medium, чтобы читать больше историй от меня и других писателей. Вы можете поддержать меня, используя мою реферальную ссылку при регистрации. Я получу комиссию без дополнительных затрат для вас.
Найди меня в LinkedIn и Kaggle!
Рекомендации
[1] NLTK, Исходный код для nltk.tag.mapping. nltk.org. https://www.nltk.org/_modules/nltk/tag/mapping.html (по состоянию на 2 августа 2022 г.)
[2] spaCy, Визуализаторы. spacy.io. https://spacy.io/usage/visualizers (по состоянию на 1 августа 2022 г.)






