ЧАСТЬ 1: ТЕОРИЯ И МАТЕМАТИЧЕСКАЯ ИНТУИЦИЯ.
В этой статье я познакомлю вас с подробным объяснением теории регрессии, визуализаций, показателей оценки и препятствий, которые необходимо преодолеть, чтобы построить надежную модель регрессии. Его реализации будут рассмотрены в моей следующей статье. Прочитав эти две статьи, поверьте мне, вы поймете почти каждый аспект проблемы регрессии.
Нажмите на ссылку, чтобы прочитать статью Все о реализации линейной регрессии (python) напрямую: https://medium.com/@saurabh62nagar/everything-about-linear-regression-df3ac4145c35
1. ВВЕДЕНИЕ
Как мы знаем, существует три основных категории машинного обучения: Контролируемое, Неконтролируемое и Подкрепление. При обучении с учителем модели обучаются на размеченном наборе данных. Линейная регрессия относится к контролируемому машинному обучению. Это позволяет прогнозировать будущие результаты, используя исторические данные.
В контролируемом машинном обучении нам нужно найти функцию сопоставления между функциями (x) и целью/меткой (y), (y = f(x)). но возникает вопрос: как должен выглядеть Y и какие значения он может принимать?
Y может принимать непрерывные или дискретные значения, в зависимости от этого контролируемое обучение делится на два типа: регрессия и классификация. Если Y принимает непрерывные данные, то это рассматривается как проблема регрессии, а если Y принимает дискретные данные/значения, то это становится проблемой классификации.
Пример для задачи регрессии: «вы хотите оценить количество осадков за день» и для задачи классификации: «оценка количества осадков в таких категориях, как низкий, средний и высокий».
В задачах регрессии y=f(x) является решением для входных данных (x) и выходных данных (y). Мы, как инженеры машинного обучения, должны найти эту функцию отображения (f). Вопрос в том, что нам дадут? и ответ «и х, и у». Как только f будет найдено, мы применим ту же функцию к новым входным данным(x) и предскажем/вычислим Y для новых входных данных, используя уравнение ,y' = f(x'), а затем мы можем сравнить фактический Y с прогнозируемым Y(y'). Это называется оценкой модели.

2. РЕГРЕСС
Линейная регрессия — это статистическая модель, используемая для анализа и понимания силы и характера взаимосвязи между двумя переменными (вход (x), выход (y)). Этот метод используется для прогнозирования, моделирования временных рядов и установления причинно-следственных связей. Таким образом, при выполнении линейной регрессии есть две задачи.
- Насколько тесно связаны x и y? Линейная регрессия дает значение от -1 до 1, что указывает на силу связи.
- Как только связь между x и y станет известна, используйте ее для прогнозирования будущих результатов, используя y = mx+c | у=а0+а1х
Линия регрессии может представлять собой положительную или отрицательную линейную зависимость. При положительной корреляции наклон регрессии также положителен, а при отрицательной корреляции наклон регрессии будет отрицательным.


2.1 ТИПЫ РЕГРЕССИИ
- Простая линейная регрессия (y=mx+c, один вход и один выход).
- Множественная линейная регрессия (несколько входов и один выход).
- Полиномиальная регрессия.
- Логистическая регрессия (используется для задач классификации).
Выше упомянуты типы регрессии, а не методы, которые используются в машинном обучении для выполнения регрессии.
2.2 МНОЖЕСТВЕННАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ
Множественная линейная регрессия — это статистический метод, который использует несколько независимых переменных для прогнозирования результата переменной отклика, в то время как в простой линейной регрессии используется только одна независимая переменная.
Y = m1x1 + m2x2 + m3x3 + ……………….+mn*xn + c
где Y — целевая (зависимая переменная), x1…xn — независимые переменные, m…..mn — наклоны и c — коэффициент/перехват.
2.4 ПОЛИНОМИАЛЬНАЯ РЕГРЕССИЯ
Полиномиальная регрессия используется для подгонки линейной модели к нелинейным точкам данных путем создания новых линейных функций за счет уменьшения мощности нелинейных функций. Поскольку для нелинейных данных линия линейной регрессии не подходит лучше всего (показано ниже на рисунке).
Пример: квадратичные функции, y = mx1 + m2x2² +c[нелинейный]
Уменьшите его, приняв x2' = x2², и тогда уравнение станет y = mx1 + m2x2' +c.

3. НЕОБХОДИМОСТЬ ЛИНЕЙНОЙ РЕГРЕССИИ
Чтобы понять это, давайте возьмем пример, предположим, что вы хотите оценить зарплату сотрудника на основе его / ее опыта из данных истории сотрудников компании. Здесь и зарплата, и опыт являются непрерывными переменными. Итак, здесь опыт является независимой переменной (x), а заработная плата — зависимой переменной (y). Проверяя связь между x и y , мы можем оценить будущую зарплату сотрудника.
4. КОРРЕЛЯЦИЯ И РЕГРЕССИЯ
КЛЮЧЕВЫЕ СХЕМЫ
- Оба количественно определяют направление и силу связи между двумя числовыми переменными.
- Когда корреляция (r) отрицательна, наклон регрессии (m) будет отрицательным.
- Когда корреляция положительна, наклон регрессии будет положительным.
- Квадрат корреляции (r2 или R2) имеет особое значение в простой линейной регрессии. Он представляет собой долю вариации Y, объясняемую X.
КЛЮЧЕВЫЕ ОТЛИЧИЯ
- Регрессия пытается установить, как X вызывает изменение Y, и результаты анализа изменятся, если X и Y меняются местами. При корреляции переменные X и Y взаимозаменяемы.
- Регрессия предполагает, что X фиксируется без ошибок, таких как величина дозы или установка температуры. При корреляции X и Y обычно являются случайными переменными, такими как рост и вес или кровяное давление и частота сердечных сокращений.
- Корреляция — это отдельная статистика, тогда как регрессия дает целое уравнение.
5. ПРЕДПОЛОЖЕНИЯ О ЛИНЕЙНОЙ РЕГРЕССИИ
Регрессия — это параметрический подход. «Параметрический» означает, что он делает предположения о данных и, следовательно, носит ограничительный характер. он не дает хороших результатов для наборов данных, которые не соответствуют его предположениям. Поэтому для построения надежной регрессионной модели важно проверить ее предположения.
Сначала давайте посмотрим, каковы предположения, а затем посмотрим, как их проверить.
- Должна существовать линейная и аддитивная связь между независимыми (x) и зависимыми (y) переменными. Линейный означает, что изменение Y из-за изменения X на одну единицу является постоянным независимо от значений X. Аддитивное означает, что влияние одной независимой переменной на Y не зависит от других переменных.
- Между остаточными терминами (ошибками) не должно быть корреляции. Отсутствие этого предположения называется автокорреляцией.
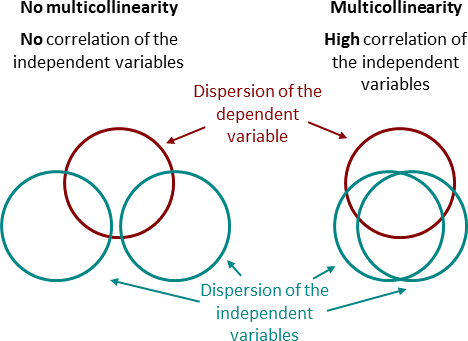
- Независимые переменныене должны коррелировать друг с другом. Отсутствие этого явления называется мультиколлинеарностью.
- Ошибка (остатки) должна иметь постоянную дисперсию, это называется гомоскедастичностью. Наличие непостоянной дисперсии ошибок называется гетероскедастичностью.
- Члены ошибки должны быть нормально распределены.
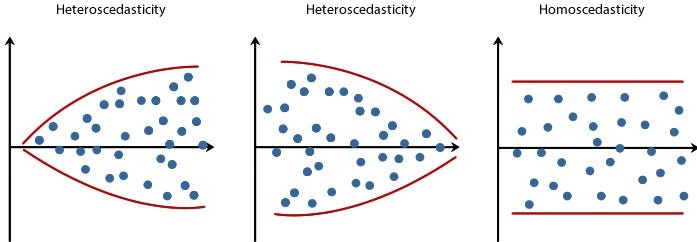
РЕШЕНИЕ. Чтобы преодолеть проблему нелинейности, вы можете применить преобразование квадратного корня или логарифмическое преобразование или box cox преобразование для предикторов(x). Для обработки гетероскедастичности выполните преобразование логарифм или квадратный корень для переменной ответа(y).
6. ПОКАЗАТЕЛИ ТОЧНОСТИ РЕГРЕССИИ
(A) R-КВАДРАТ:R-квадрат показывает, насколько вариации в «отклике» объясняются независимыми переменными. это наиболее распространенный показатель для оценки эффективности регрессионных моделей. его значение находится в диапазоне от 0 до 1, т.е. от 0% до 100%.
Пример: если значение R-квадрата равно 16%, это означает, что у нас есть только 16% информации для точных прогнозов. «Чем больше R-квадрат, тем лучше модель».

НЕДОСТАТКИ R-SQUARE: предполагается, что каждая независимая (x) переменная в модели объясняет изменение зависимой (y) переменной, поэтому она просто остается неизменной или увеличивается при добавлении большего количества предикторов.
(B) Скорректированный R-квадрат: Всегда следует проверять скорректированный R-квадрат, так как его значение увеличивается только в том случае, если добавленная независимая переменная улучшает объяснение вариации зависимой переменной. Если модель не улучшается, то значение скорректированного R-квадрата уменьшается.

(C) ФУНКЦИЯ ЗАТРАТ:Это основано на «обычном методе регрессии наименьших квадратов» [МНК]. При линейной регрессии у нас может быть несколько линий для разных значений наклонов и точек пересечения. Но главный вопрос, который возникает, заключается в том, какая из этих линий на самом деле представляет правильное соотношение между X и Y, то есть «какая линия лучше всего подходит?». Метод OLS гласит: «Линия, которая имеет минимальную общую сумму квадратов разностей, будет наиболее подходящей линией». Чтобы выяснить это, мы можем использовать в качестве параметра среднеквадратичную ошибку или MSE. Для линейной регрессии эта MSE представляет собой не что иное, как Функция стоимости.
MSE – это сумма квадратов разностей между прогнозируемыми и фактическими значениями. Выходные данные представляют собой одно число, представляющее затраты. Таким образом, линия с функцией минимальной стоимости или MSE наилучшим образом представляет отношение между X и Y. И когда у нас есть наклон и точка пересечения линии, дающей наименьшую ошибку, мы можем использовать эту линию для предсказания Y.
Как и MSE, у нас также есть среднеквадратическая ошибка (RMSE), средняя абсолютная ошибка(MAE) и средняя абсолютная ошибка в процентах (MAPE). Но мы должны выбрать MSE, а не MAE, потому что это усиливает условия ошибки и указывает, даже если ошибка небольшая, но ее влияние может быть огромным.

Я бы посоветовал изучить некоторые другие термины, такие как: TSS, RSS и остатки (ошибки).
7. ГРАДИЕНТНЫЙ СПУСК
Градиентный спуск – это метод обновления значений m и c для минимизации функции стоимости. Модель регрессии использует градиентный спуск для случайного выбора и автоматического обновления этих значений и минимизации функции стоимости. Поэтому мы можем сказать, что «градиентный спуск — это алгоритм оптимизации, который итеративно настраивает параметры (m и c), чтобы минимизировать функцию стоимости до минимально возможного значения».

Используя приведенную выше формулу, он пытается итеративно обновить m и c, пока не минимизирует функцию стоимости и не достигнет минимального значения наклона (m).

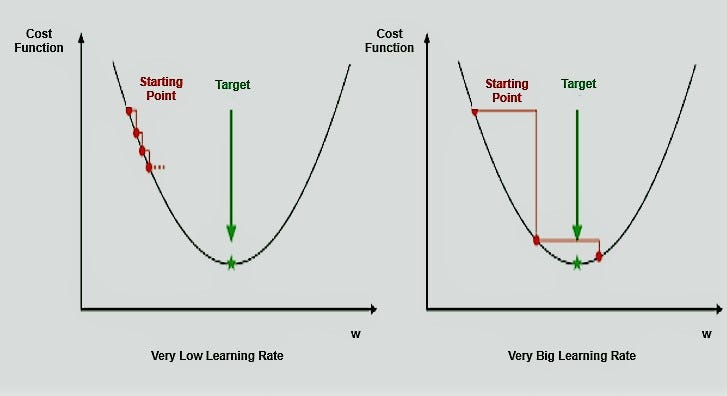
Ваша модель перестает обучаться, когда градиент (наклон) равен нулю или близок к нулю.
8. ОЦЕНКА КОЭФФИЦИЕНТОВ
В регрессионном анализе значения p и коэффициенты вместе указывают, какие связи в модели являются статистически значимыми. Коэффициенты описывают математическую связь между каждой независимой переменной и зависимой переменной. в то время как P-значения для коэффициентов указывают, являются ли эти отношения значимыми.
P ‹ 0,05: отклонить значение null (значительно, сохранить переменную).
P›0,05: принять значение Null (не имеет значения, отбросить переменную)
9. ПРОБЛЕМЫ ПРОГНОЗИРОВАНИЯ

(A). НЕ ПОДГОНКА: Если обучение модели плохое, это означает, что ваша модель не может правильно соответствовать данным, тогда обучение модели будет плохим. В этой ситуации ваша модель не будет работать должным образом, даже на обучающем наборе данных. Эта ситуация называется проблемой недообучения. Следовательно, в этом случае точность как для поезда, так и для тестового набора данных.
Чтобы справиться с этой проблемой, выполните повторную очистку, предварительную обработку и повторное обучение ваших данных.
(Б). ЧРЕЗМЕРНАЯ ПОДГОТОВКА: когда вы строго обучаете свою модель, это означает, что вы пытаетесь подогнать модель по каждой точке данных. В этом случае модель будет работать лучше всего в наборе данных поезда, но она не будет работать в тестовом / новом наборе данных. . Таким образом, точность тестовых прогнозов будет очень низкой по сравнению с прогнозами обучающих данных. Эта проблема возникает главным образом из-за «мультиколлинеарности» данных.
Итак, вопрос в том, как преодолеть эту ситуацию?
Методы регуляризации решают проблему переобучения . Мы можем использовать алгоритмы машинного обучения Ridge и регрессия Лассо для обработки. мы обсудим их во время части реализации в следующем разделе.
МУЛЬТИКОЛЛИНЕАРНОСТЬ: когда две или более переменных, которые коррелируют между собой, пытаются объяснить ответную переменную, это называется мультиколлинеарностью. Приведу пример:
«Место преступления и следователь»
Предположим, офицер, занимающийся инвестициями, осматривает место преступления, и есть 3 свидетеля, и двое из них рассказывают одну и ту же историю, а 1 рассказывает другую историю о преступлении.
Вопрос : Должен ли офицер посетить всех троих для дальнейшего расследования или только 2 из них, 1 из 2 (свидетелей одной и той же истории) и еще одного человека?
Ответ:Офицер должен рассмотреть только 02 свидетелей для дальнейшего расследования, чтобы получить четкое представление о месте преступления и сэкономить энергию и время.
Поэтому, когда у вас есть набор данных:
Рассчитать корреляцию каждой независимой переменной с зависимой переменной и корреляцию независимых переменных между собой.
Корреляция должна быть нулевой или низкой среди независимых переменных и высокой между независимыми и зависимыми переменными.
На этом теоретическая часть регрессии заканчивается. Если вам понравилась эта конкретная статья, пожалуйста, нажмите кнопку аплодисментов. Не забудьте прочитать ЧАСТЬ 02 этой статьи, чтобы завершить свое практическое понимание ЛИНЕЙНОЙ РЕГРЕССИИ. Нажмите на ссылку: https://medium.com/@saurabh62nagar/everything-about-linear-regression-df3ac4145c35
СПАСИБО!






