
Создание, загрузка и визуализация прогнозов модели YOLOv8
Добро пожаловать в первую часть нашей серии из трех частей о YOLOv8! В этой серии мы покажем вам, как работать с YOLOv8, от загрузки готовых моделей до точной настройки этих моделей для конкретных случаев использования и всего, что между ними.
На протяжении всей серии мы будем использовать две библиотеки: FiftyOne, набор инструментов компьютерного зрения с открытым исходным кодом, и Ultralytics, библиотеку, которая даст нам доступ к YOLOv8.
В части 1 вы узнаете, как создавать, загружать и визуализировать прогнозы YOLOv8. Во Части 2 мы покажем вам, как оценить качество прогнозов модели YOLOv8. В Части 3 мы завершим, проведя вас через процесс тонкой настройки YOLOv8 для ваших приложений компьютерного зрения.
Этот пост организован следующим образом:
- История семьи YOLO
- Настройка с YOLOv8
- Генерация прогнозов YOLOv8
- Визуализация прогнозов YOLOv8 с помощью приложения FiftyOne
Продолжайте читать, чтобы узнать, как вы можете использовать FiftyOne, чтобы глубже изучить прогнозы YOLOv8!
Фон
С момента своего первого выпуска в 2015 году семейство моделей компьютерного зрения You Only Look Once (YOLO) было одним из самых популярных в этой области. Основное новшество архитектуры YOLO заключалось в том, чтобы рассматривать задачи обнаружения объектов как проблемы регрессии, чтобы модель одновременно генерировала прогнозы для всех ограничивающих рамок объектов и вероятностей классов.
Этот подход представлял собой серьезный сдвиг по сравнению с предыдущими современными моделями обнаружения объектов, в которых каждый обнаруженный объект представлял собой повышенную нагрузку на вывод — отсюда и прозвище You Only Look Once или YOLO. А за счет оптимизации конвейера прогнозирования YOLO значительно сократил время вывода. Оригинальная модель YOLO могла обрабатывать 45 кадров в секунду!
За последние восемь лет эта архитектурная инновация породила семейство моделей YOLO, каждое поколение которых улучшало скорость и точность. Модели были обучены на новых наборах данных. Архитектура была расширена до новых областей, как с высоты птичьего полета. И сквозной детектор использовался во все большем количестве приложений.
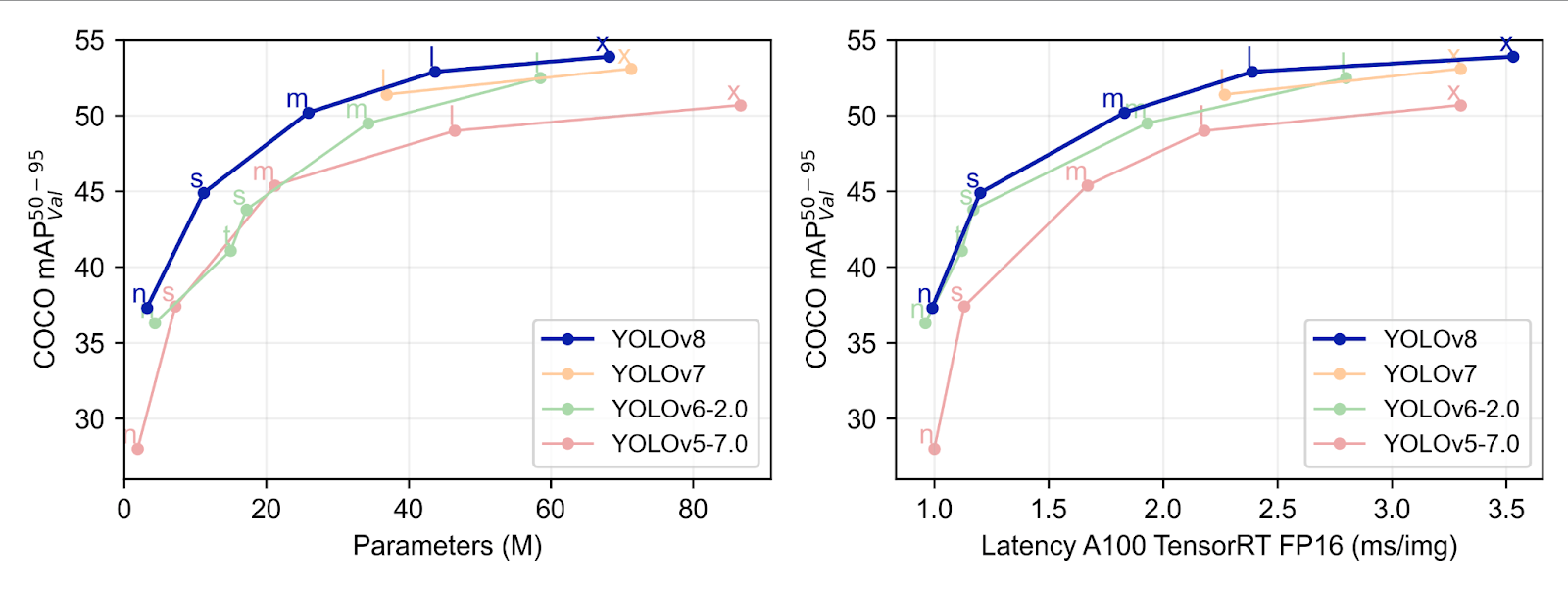
В конце 2022 года Ultralytics анонсировала последнего члена семейства YOLO, YOLOv8, который поставляется с новой основой. Модель на самом деле представляет собой набор моделей для обнаружения объектов и сегментации экземпляров. Набор включает в себя модели различных размеров, от 3,2 миллиона параметров до 68,2 миллиона параметров, которые достигают современного уровня производительности и сохраняют скорость своих предшественников.
Однако в YOLOv8 базовые модели обнаружения и сегментации являются универсальными, а это означает, что для пользовательских вариантов использования они могут не подходить из коробки.
В этой серии мы покажем вам, как более подробно изучить прогнозы YOLOv8, а затем использовать эти идеи для тонкой настройки модели для ваших собственных приложений.
Начиная
Если вы еще этого не сделали, установите пакеты Python Ultralytics и FiftyOne:
pip install fiftyone ultralytics
Мы также импортируем все остальные соответствующие пакеты Python:
import numpy as np import os from tqdm import tqdm
Далее мы импортируем соответствующие модули из FiftyOne. Базовая библиотека FiftyOne позволит нам эффективно работать с данными нашего компьютерного зрения. Мы будем использовать FiftyOne Dataset Zoo для загрузки подмножеств набора данных MS COCO. А ViewField позволит нам символически фильтровать данные в нашем наборе данных.
import fiftyone as fo import fiftyone.zoo as foz from fiftyone import ViewField as F
Наконец, мы можем импортировать объект YOLO из Ultralytics и использовать его для создания предварительно обученных моделей обнаружения и сегментации в Python. Наряду с архитектурой YOLOv8 компания Ultralytics выпустила набор предварительно обученных моделей разного размера для задач классификации, обнаружения и сегментации.
В целях иллюстрации мы будем использовать самую маленькую версию YOLOv8 Nano (YOLOv8n), но тот же синтаксис будет работать для любой из предварительно обученных моделей в репозитории Ultralytics YOLOv8 GitHub.
from ultralytics import YOLO
detection_model = YOLO("yolov8n.pt")
seg_model = YOLO("yolov8n-seg.pt")
В этой серии сообщений в блоге мы будем вызывать модели YOLOv8 из командной строки в большинстве случаев. Однако в качестве иллюстрации мы покажем, как использовать эти модели в среде Python.
В Python вы можете применить модель YOLOv8 к отдельному изображению, передав путь к файлу в вызове модели. Для образа с путем к файлу path/to/image.jpg выполняется
detection_model("path/to/image.jpg")
создаст список, содержащий один объект ultralytics.yolo.engine.results.Results. Аналогичный результат можно получить, если применить модель сегментации к изображению. Эти результаты содержат ограничивающие рамки, оценки достоверности классов и целые числа, представляющие метки классов. Полное обсуждение этих объектов результатов см. в Ultralytics YOLOv8 Справочник по API результатов.
Если мы хотим запускать задачи для всех изображений в каталоге, мы можем сделать это из командной строки с помощью Интерфейса командной строки YOLO, указав задачу [detect, segment, classify] и режим [train, val, predict, export] вместе с другими аргументами.
Чтобы выполнить вывод на наборе изображений, мы должны сначала поместить данные в соответствующий формат. Лучший способ сделать это — загрузить ваши изображения в FiftyOne Dataset, а затем экспортировать набор данных в формате YOLOv5Dataset, поскольку YOLOv5 и YOLOv8 используют одни и те же форматы данных.
Например, если все ваши изображения находятся в каталоге my_image_dir, вы можете загрузить изображения с помощью метода from_dir():
dataset = fo.Dataset.from_dir(
dataset_dir="my_image_dir",
dataset_type=fo.types.ImageDirectory
)
Затем экспортируйте набор данных в новый каталог my_yolo_dir в правильном формате, который создаст каталог и заполнит его подкаталогом images, а также файлом dataset.yaml YAML:
dataset.export(
export_dir=`my_yolo_dir`,
dataset_type=fo.types.YOLOv5Dataset
)
Вскоре мы будем использовать несколько более общий экспорт, чтобы учитывать метки истинности, классы меток и разбиение наборов данных.
Теперь мы можем запустить вывод с моделью обнаружения YOLOv8n:
yolo task=detect mode=predict model=yolov8n.pt source=/my_yolo_dir/images/val save_txt=True save_conf=True
Но как узнать, хороши ли эти прогнозы? Прежде чем мы развернем модель в производственной среде, нам нужно понять, что она делает и каковы ее ограничения. Итак, давайте более подробно рассмотрим, что делает YOLOv8!
Генерация и загрузка прогнозов YOLOv8
Первый шаг к пониманию YOLOv8 — это визуализация его прогнозов. Для этого воспользуемся FiftyOne App.
Для простоты мы рассмотрим прогнозы YOLOv8 для подмножества набора данных MS COCO. Это набор данных, на котором эти модели были обучены, а это означает, что они, вероятно, продемонстрируют близкую к пиковой производительность на этих данных. Кроме того, работа с данными COCO упрощает сопоставление выходных данных модели с метками классов.
Давайте загрузим изображения и обнаруженные объекты достоверности в набор проверки COCO из Пятидесяти одного зоопарка набора данных.
dataset = foz.load_zoo_dataset(
'coco-2017',
split='validation',
)
Мы также можем сгенерировать сопоставление прогнозов классов YOLO с метками классов COCO. COCO имеет 91 класс, а YOLOv8, как и YOLOv3 и YOLOv5, игнорирует все числовые классы и сосредотачивается на оставшихся 80.
coco_classes = [c for c in dataset.default_classes if not c.isnumeric()]
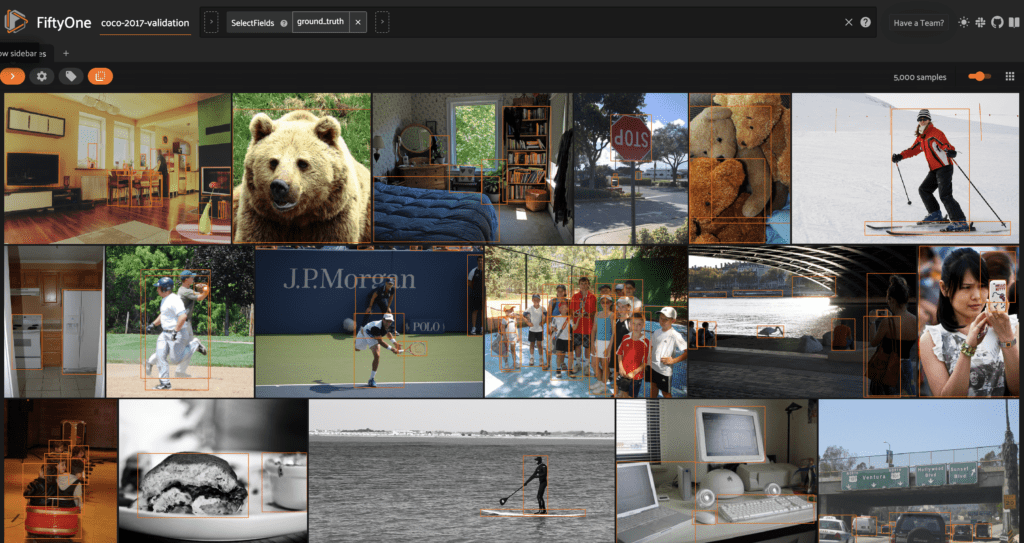
Прежде чем добавлять прогнозы YOLOv8, мы можем визуализировать эти данные в FiftyOne App, запустив сеанс:
session = fo.launch_app(dataset)
Теперь давайте создадим прогнозы обнаружения для этих изображений из командной строки, как в примере выше. Для дальнейшего удобства мы используем этот более общий метод export_yolo_data().
def export_yolo_data(
samples,
export_dir,
classes,
label_field = "ground_truth",
split = None
):
if type(split) == list:
splits = split
for split in splits:
export_yolo_data(
samples,
export_dir,
classes,
label_field,
split
)
else:
if split is None:
split_view = samples
split = "val"
else:
split_view = samples.match_tags(split)
split_view.export(
export_dir=export_dir,
dataset_type=fo.types.YOLOv5Dataset,
label_field=label_field,
classes=classes,
split=split
)
Для этих данных команды экспорта и вывода выглядят следующим образом:
coco_val_dir = "coco_val" export_yolo_data(dataset, coco_val_dir, coco_classes)
И:
yolo task=detect mode=predict model=yolov8n.pt source=coco_val/images/val save_txt=True save_conf=True
Теперь пришло время добавить прогнозы YOLOv8 для этих изображений в наш набор данных. Когда мы запускаем задачу вывода YOLOv8 из командной строки, прогнозы сохраняются в файле .txt. Для обнаружения эти текстовые файлы содержат одну строку для каждого обнаружения объекта на изображении: целое число для метки класса, показатель достоверности класса и четыре значения, представляющие ограничивающую рамку.
Мы можем прочитать файл предсказания обнаружения YOLOv8 с N обнаружениями в массив (N, 6) numpy:
def read_yolo_detections_file(filepath):
detections = []
if not os.path.exists(filepath):
return np.array([])
with open(filepath) as f:
lines = [line.rstrip('\n').split(' ') for line in f]
for line in lines:
detection = [float(l) for l in line]
detections.append(detection)
return np.array(detections)
Отсюда нам нужно преобразовать эти обнаружения в формат FiftyOne Detections.
YOLOv8 представляет ограничивающие рамки в центрированном формате с координатами [center_x, center_y, width, height], тогда как FiftyOne хранит ограничивающие рамки в формате [top-left-x, top-left-y, width, height]. Мы можем сделать это преобразование, отцентрировав предсказанные ограничивающие рамки:
def _uncenter_boxes(boxes):
'''convert from center coords to corner coords'''
boxes[:, 0] -= boxes[:, 2]/2.
boxes[:, 1] -= boxes[:, 3]/2.
Кроме того, мы можем преобразовать список прогнозов классов (индексов) в список меток классов (строк), передав список классов:
def _get_class_labels(predicted_classes, class_list):
labels = (predicted_classes).astype(int)
labels = [class_list[l] for l in labels]
return labels
Учитывая результат вызова read_yolo_detections_file(), yolo_detections, мы можем сгенерировать объект FiftyOne Detections, который собирает эти данные:
def convert_yolo_detections_to_fiftyone(
yolo_detections,
class_list
):
detections = []
if yolo_detections.size == 0:
return fo.Detections(detections=detections)
boxes = yolo_detections[:, 1:-1]
_uncenter_boxes(boxes)
confs = yolo_detections[:, -1]
labels = _get_class_labels(yolo_detections[:, 0], class_list)
for label, conf, box in zip(labels, confs, boxes):
detections.append(
fo.Detection(
label=label,
bounding_box=box.tolist(),
confidence=conf
)
)
return fo.Detections(detections=detections)
Последний ингредиент — это функция, которая принимает путь к файлу изображения и возвращает путь к файлу соответствующего текстового файла предсказания обнаружения YOLOv8.
def get_prediction_filepath(filepath, run_number = 1):
run_num_string = ""
if run_number != 1:
run_num_string = str(run_number)
filename = filepath.split("/")[-1].split(".")[0]
return "runs/detect/predict{}/labels/".format(run_num_string) + filename + ".txt"
Обратите внимание, что если вы запускаете несколько вызовов логического вывода для одной и той же задачи, результаты прогнозов сохраняются в каталоге со следующим доступным целым числом, добавляемым к predict в пути к файлу. Вы можете учесть это в приведенной выше функции, передав аргумент run_number.
Собрав части вместе, мы можем написать функцию, которая эффективно добавляет эти обнаружения YOLOv8 ко всем образцам в нашем наборе данных, объединяя операции чтения и записи в базовую базу данных MongoDB.
def add_yolo_detections(
samples,
prediction_field,
prediction_filepath,
class_list
):
prediction_filepaths = samples.values(prediction_filepath)
yolo_detections = [read_yolo_detections_file(pf) for pf in prediction_filepaths]
detections = [convert_yolo_detections_to_fiftyone(yd, class_list) for yd in yolo_detections]
samples.set_values(prediction_field, detections)
Теперь мы можем быстро добавить обнаружения в несколько строк кода:
filepaths = dataset.values("filepath")
prediction_filepaths = [get_prediction_filepath(fp) for fp in filepaths]
dataset.set_values(
"yolov8n_det_filepath",
prediction_filepaths
)
add_yolo_detections(
dataset,
"yolov8n",
"yolov8n_det_filepath",
coco_classes
)
Визуализация прогнозов YOLOv8
Первым шагом к пониманию того, что делает модель компьютерного зрения, также должна быть визуализация прогнозов модели на ваших данных. Мы можем сделать это в приложении FiftyOne:
session = fo.launch_app(dataset)
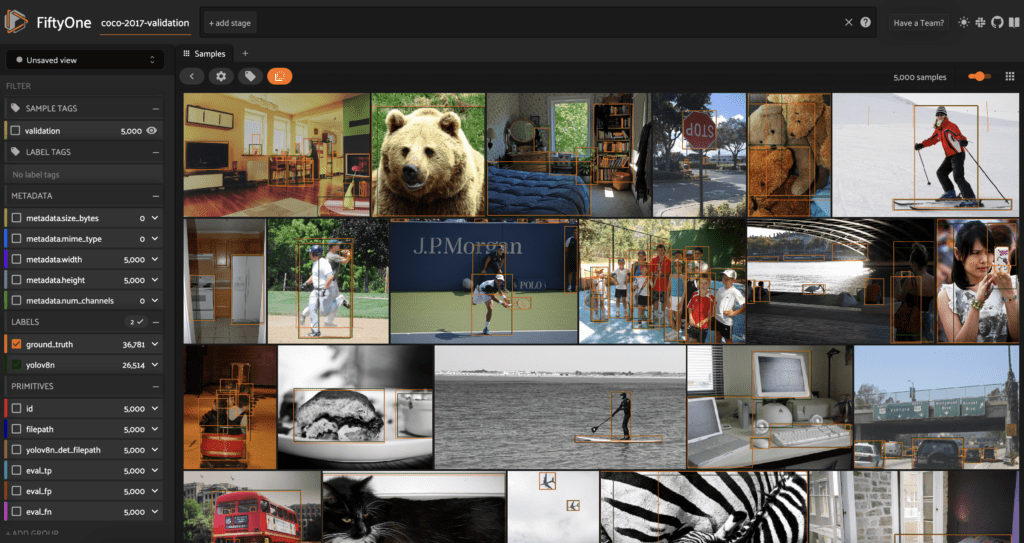
Если мы хотим показывать только прогнозы, мы можем снять флажок ground_truth на боковой панели слева. Мы также можем просмотреть более подробную информацию о метках на отдельном изображении, щелкнув изображение в сетке образцов, которая открывается в расширенном модальном окне.

Здесь мы можем видеть основную истину и предсказанные метки классов, а также доверительные вероятности класса.
Мы можем отфильтровать прогнозы с высокой достоверностью, используя ползунок confidence на боковой панели слева под заголовком метки yolov8n:
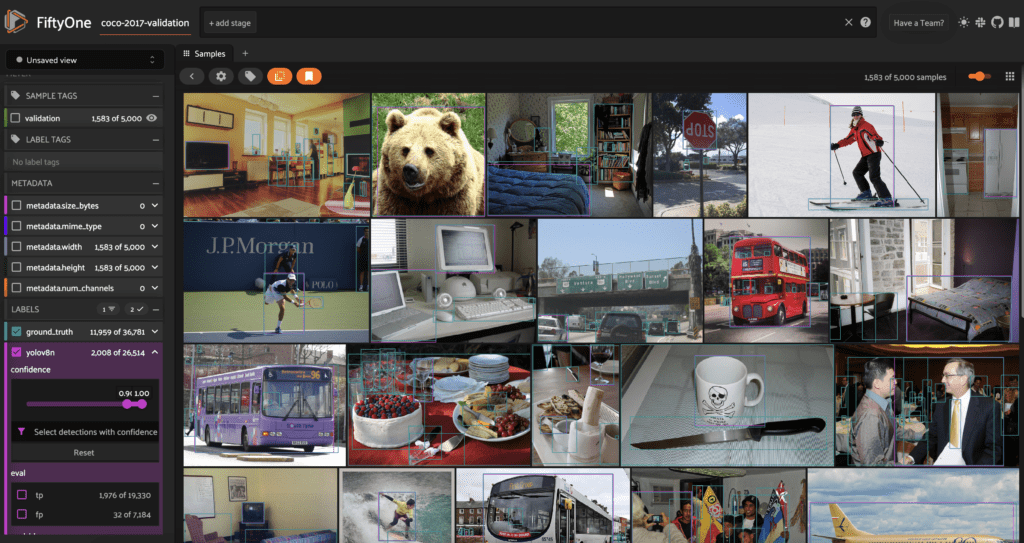
Мы видим, что если мы отфильтруем прогнозы с помощью confidence >= 0.9, мы получим только 2008 из 26 000+ прогнозов, сгенерированных при запуске модели в наборе данных.
Также стоит отметить, что прогнозы YOLOv8 можно преобразовывать непосредственно из вывода вызова модели YOLO в Python, без предварительного создания внешних файлов прогнозов и их чтения. Давайте посмотрим, как это можно сделать для сегментации экземпляров.
Как и обнаружения, YOLOv8 хранит сегментации экземпляров с ограничивающими рамками по центру. Кроме того, YOLOv8 хранит маску, которая покрывает все изображение, и только прямоугольная область этой маски содержит ненулевые значения. FiftyOne, с другой стороны, сохраняет сегментации экземпляров на Detection метках с маской, которая покрывает только заданную ограничивающую рамку.
Мы можем преобразовать сегментацию экземпляра YOLOv8 в сегментацию экземпляра FiftyOne с помощью этой функции convert_yolo_segmentations_to_fiftyone():
def convert_yolo_segmentations_to_fiftyone(
yolo_segmentations,
class_list
):
detections = []
boxes = yolo_segmentations.boxes.xywhn
if not boxes.shape or yolo_segmentations.masks is None:
return fo.Detections(detections=detections)
_uncenter_boxes(boxes)
masks = yolo_segmentations.masks.masks
labels = _get_class_labels(yolo_segmentations.boxes.cls, class_list)
for label, box, mask in zip(labels, boxes, masks):
## convert to absolute indices to index mask
w, h = mask.shape
tmp = np.copy(box)
tmp[2] += tmp[0]
tmp[3] += tmp[1]
tmp[0] *= h
tmp[2] *= h
tmp[1] *= w
tmp[3] *= w
tmp = [int(b) for b in tmp]
y0, x0, y1, x1 = tmp
sub_mask = mask[x0:x1, y0:y1]
detections.append(
fo.Detection(
label=label,
bounding_box = list(box),
mask = sub_mask.astype(bool)
)
)
return fo.Detections(detections=detections)
Перебирая все образцы в наборе данных, мы можем добавить прогнозы из нашего seg_model, а затем просмотреть эти предсказанные маски в приложении FiftyOne.
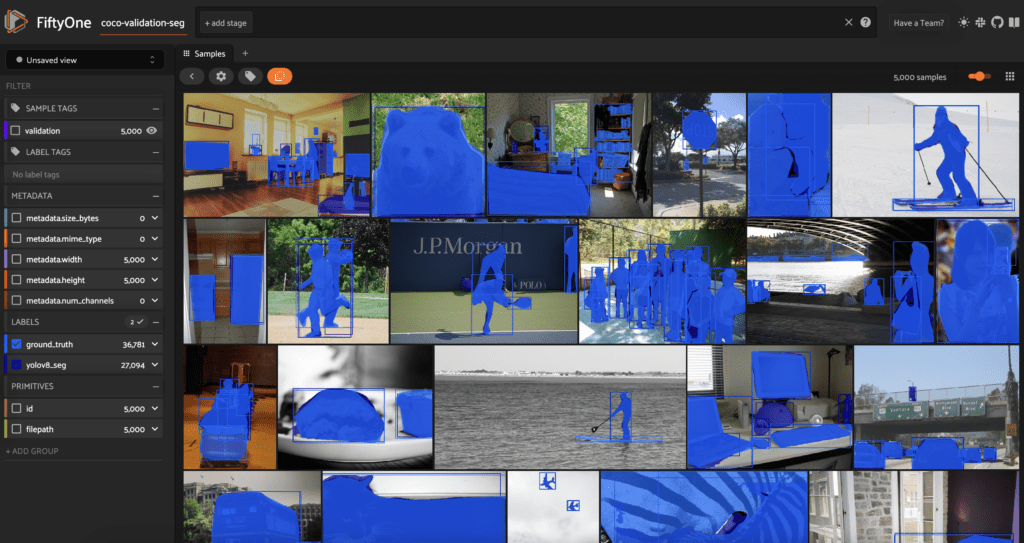
Заключение
В этой статье мы продемонстрировали, как начать использовать модели YOLOv8 для ваших данных и как визуализировать прогнозы модели YOLOv8 на изображениях. В Части 2, используя те же проверочные изображения и метки COCO, мы покажем вам, как оценить качество прогнозов модели YOLOv8, определить крайние случаи и оценить потенциальные режимы отказа.
Продолжить Часть 2!
Присоединяйтесь к сообществу FiftyOne!
Присоединяйтесь к тысячам инженеров и специалистов по данным, уже использующих FiftyOne для решения некоторых из самых сложных задач в области компьютерного зрения уже сегодня!
- 1350+ участников FiftyOne Slack
- 2500+ звезд на GitHub
- 3000+ Участников встречи
- Использовано 250+ репозиториев
- 55+ авторов
Что дальше?
- Если вам нравится то, что вы видите на GitHub, поставьте звезду проекту.
- "Начать!" Мы упростили запуск и запуск за несколько минут.
- Присоединяйтесь к сообществу Slack FiftyOne, мы всегда рады помочь.
Первоначально опубликовано на https://voxel51.com 21 февраля 2023 г.






